OLAP 기술. 재무 관리 olap 시스템의 OLAP
최근에 OLAP에 대해 많은 글이 작성되었습니다. 우리는 이러한 기술 주위에 약간의 붐이 있다고 말할 수 있습니다. 사실, 우리에게 이 붐은 다소 늦었지만 이것은 물론 국가의 일반적인 상황 때문입니다.
엔터프라이즈 규모의 정보 시스템에는 일반적으로 데이터, 역학, 추세 등의 복잡한 다차원 분석을 위해 설계된 응용 프로그램이 포함됩니다. 이러한 분석은 궁극적으로 의사 결정을 지원하기 위한 것입니다. 종종 이러한 시스템을 의사결정 지원 시스템이라고 합니다.
의사 결정 지원 시스템에는 일반적으로 초기 세트의 다양한 샘플에 대한 집계 데이터를 지각 및 분석에 편리한 형태로 사용자에게 제공하는 수단이 있습니다. 원칙적으로 이와 같은 집계 함수다차원(따라서 비관계형) 데이터 세트(하이퍼큐브 또는 메타큐브라고도 함)를 형성합니다. 축에는 매개변수가 포함되어 있고 셀에는 매개변수에 의존하는 집계 데이터가 포함되어 있습니다. 이러한 데이터는 관계형 테이블에도 저장할 수 있습니다. 그러나 이 경우 스토리지의 물리적 구현이 아니라 데이터의 논리적 구성에 대해 이야기하고 있습니다. 각 축을 따라 데이터를 다양한 세부 수준을 나타내는 계층 구조로 구성할 수 있습니다. 이 데이터 모델을 사용하여 사용자는 다음을 공식화할 수 있습니다. 복잡한 쿼리, 보고서 생성, 데이터 하위 집합 가져오기
복잡한 다차원 데이터 분석 기술을 OLAP(On-Line Analytical Processing)라고 합니다.
OLAP는 데이터 웨어하우징의 핵심 구성 요소입니다.
OLAP의 개념은 잘 알려진 데이터베이스 연구원이자 관계형 데이터 모델의 저자인 Edgar Codd가 1993년에 설명했습니다.E.F. 코드, S.B. Codd 및 C.T.Salley, 사용자 분석가에게 OLAP(온라인 분석 처리) 제공: IT 의무.기술 보고서, 1993).
1995년에 Codd가 설명한 요구 사항을 기반으로 다차원 분석 응용 프로그램에 대한 다음 요구 사항을 포함하는 소위 FASMI 테스트(공유된 다차원 정보의 빠른 분석 - 공유된 다차원 정보의 빠른 분석)가 공식화되었습니다.
· 사용자에게 허용 가능한 시간(보통 5초 이하)에 분석 결과를 제공하는 것, 비록 덜 상세한 분석을 희생하더라도
· 이 응용 프로그램과 관련된 논리적 및 통계적 분석을 수행하고 최종 사용자가 액세스할 수 있는 형식으로 저장할 수 있는 기능
· 적절한 잠금 메커니즘 및 승인된 액세스 도구를 지원하는 데이터에 대한 다중 사용자 액세스
· 계층 및 다중 계층에 대한 완전한 지원을 포함하여 데이터의 다차원 개념 표현(이것이 OLAP의 핵심 요구 사항임)
· 볼륨 및 저장 위치에 관계없이 필요한 정보에 액세스할 수 있는 기능.
OLAP 기능을 구현할 수 있습니다. 다른 방법들, 사무용 애플리케이션의 가장 단순한 데이터 분석 도구에서 시작하여 서버 제품을 기반으로 하는 분산 분석 시스템으로 끝납니다.사용자는 자신의 작업에 적용된 다차원 구조의 데이터를 쉽게 볼 수 있습니다.
2. OLAP이란?
OLAP - English On-Line Analytical Processing의 약자 -는 특정 제품의 이름이 아니라 전체 기술의 이름입니다. 러시아어에서는 OLAP 운영 분석 처리를 호출하는 것이 가장 편리합니다. 일부 간행물에서는 분석 처리를 온라인 및 대화식이라고 부르지만 형용사 "온라인"은 OLAP 기술의 의미를 가장 정확하게 반영합니다.
경영 관리 결정의 개발은 자동화하기 가장 어려운 영역의 범주에 속합니다. 그러나 오늘날에는 의사 결정 개발 과정에서 관리자를 지원할 수 있는 기회가 있으며 가장 중요한 것은 결정 개발 프로세스, 선택 및 채택 속도를 크게 높일 수 있습니다. 이를 위해 OLAP를 사용할 수 있습니다.
솔루션 개발 프로세스가 일반적으로 어떻게 발생하는지 고려하십시오.
역사적으로 운영 활동을 자동화하는 솔루션이 가장 많이 개발되었습니다. 우리는 단순히 운영 시스템이라고 하는 OLTP(트랜잭션 데이터 처리) 시스템에 대해 이야기하고 있습니다. 이러한 시스템은 특정 사실의 등록, 아카이브의 단기 저장 및 보존을 보장합니다. 이러한 시스템의 기반은 관계형 데이터베이스 관리 시스템(RDBMS)에 의해 제공됩니다. 전통적인 접근 방식은 의사 결정 지원을 위해 이미 구축된 운영 시스템을 사용하는 것입니다. 일반적으로 그들은 운영 체제에 대한 개발된 쿼리 시스템을 구축하고 결정을 지원하기 위해 직접 해석 후 받은 보고서를 사용하려고 합니다. 보고서는 사용자 정의 기반으로 작성할 수 있습니다. 관리자는 보고서를 요청하고 정기적으로 특정 이벤트 또는 시간에 도달하면 보고서가 작성됩니다. 예를 들어, 전통적인 의사 결정 지원 프로세스는 다음과 같습니다. 관리자가 정보 전문가에게 가서 자신의 질문을 공유합니다. 그런 다음 정보 전문가는 운영 시스템에 대한 요청을 작성하고 전자 보고서를 수신하여 해석한 다음 관리 담당자에게 알려줍니다. 물론 이러한 방식은 의사결정 지원을 어느 정도 제공하지만 효율성이 매우 낮고 많은 단점이 있습니다. 중요한 결정을 지원하는 데 소량의 데이터가 사용됩니다. 다른 문제도 있습니다. 이러한 절차는 요청을 작성하고 전자 보고서를 해석하는 과정이 길기 때문에 매우 느립니다. 리더가 지금 당장, 즉시 결정을 내려야 하는 시기에 여러 날이 걸립니다. 보고를 받은 후 관리자가 다른 문제에 관심을 가질 수 있다는 점(예: 다른 컨텍스트에서 데이터를 명확히 하거나 고려해야 함)을 고려하면 이 느린 주기를 반복해야 하며 데이터 분석 프로세스가 운영 체제반복적으로 발생하면 더 많은 시간이 소요됩니다. 또 다른 문제는 정보 기술 전문가와 관리자가 서로 다른 범주에서 생각할 수 있고 결과적으로 서로를 이해하지 못하는 서로 다른 활동 영역의 문제입니다. 그런 다음 추가 개선 반복이 필요할 것이며, 이것은 항상 충분하지 않은 시간입니다. 또 다른 중요한 문제는 이해해야 할 보고서의 복잡성입니다. 관리자는 보고서에서 관심 있는 숫자를 선택할 시간이 없습니다. 특히 숫자가 너무 많을 수 있기 때문입니다(실제로 여러 페이지를 사용하고 나머지는 만일을 대비하여 사용하는 거대한 다중 페이지 보고서를 기억하십시오). 우리는 또한 통역 작업이 정보 부서의 전문가에게 가장 자주 맡겨진다는 점에 주목합니다. 즉, 유능한 전문가는 다이어그램 그리기 등에 대한 일상적이고 비효율적인 작업으로 인해 산만 해지며 물론 자격에 유리하게 영향을 줄 수 없습니다. 또한, 들어오는 정보의 의도적인 왜곡에 관심이 있는 통역 체인에 선의를 가진 사람들이 있다는 것은 비밀이 아닙니다.
위의 단점은 운영 시스템을 만드는 비용이 작업의 효율성에 의해 적절한 정도로 보상되지 않기 때문에 운영 시스템의 전반적인 효율성과 그 존재와 관련된 비용에 대해 생각하게 만듭니다.
사실, 이러한 문제는 운영 체제의 품질이 좋지 않거나 성공적이지 못한 구성의 결과가 아닙니다. 문제의 근원은 운영 시스템에 의해 자동화되는 운영 활동과 개발 및 의사 결정 활동 간의 근본적인 차이에 있습니다. 이 차이점은 운영 체제의 데이터가 단순히 발생한 일부 이벤트의 기록, 즉 사실일 뿐 일반적인 의미의 정보가 아니라는 사실에 있습니다. 정보는 모든 영역에서 불확실성을 줄이는 것입니다. 그리고 정보가 결정 준비의 불확실성을 줄인다면 매우 좋을 것입니다. 악명 높은 E.F. 1970년대에 관계형 데이터베이스 관리 시스템 기술을 개척한 사람인 Codd는 다음과 같이 말했습니다. ". 우리는 정보의 합성, 운영 체제의 데이터를 정보로, 심지어 정성적 평가로 바꾸는 방법에 대해 이야기하고 있습니다. OLAP를 사용하면 이 변환을 수행할 수 있습니다.
OLAP은 다차원 데이터 모델의 아이디어를 기반으로 합니다. 인간의 사고는 정의상 다차원적입니다. 사람이 질문을 할 때 그는 제한을 부과하여 다차원의 질문을 공식화하므로 다차원 모델의 분석 과정은 인간 사고의 현실에 매우 가깝습니다. 다차원 모델의 차원에 따라 기업 활동에 영향을 미치는 요소(예: 시간, 제품, 회사 부서, 지리 등)가 연기됩니다. 따라서 하이퍼 큐브가 얻어집니다 (물론 큐브는 일반적으로 동일한 모서리를 가진 그림으로 이해되기 때문에 이름은별로 좋지 않습니다.이 경우에는 그렇지 않음) 표시기로 채워집니다. 기업 활동 (가격, 판매, 계획, 이익, 손실 등) 등). 이 채우기는 운영 체제의 실제 데이터로 수행할 수 있으며 과거 데이터를 기반으로 예측할 수 있습니다. Hypercube 차원은 복잡하고 계층적일 수 있으며 차원 간에 관계를 설정할 수 있습니다. 분석하는 동안 사용자는 데이터에 대한 관점을 변경할 수 있습니다(소위 논리적 관점을 변경하는 작업). 따라서 다른 섹션에서 데이터를 보고 특정 문제를 해결할 수 있습니다. 예측 및 조건부 스케줄링(가정 분석)을 포함하여 큐브에서 다양한 작업을 수행할 수 있습니다. 또한 작업은 큐브에서 한 번에 수행됩니다. 예를 들어, 제품은 하이퍼큐브 제품을 생성하며, 각 셀은 해당 승수 하이퍼큐브의 셀의 제품입니다. 당연히 차원 수가 다른 하이퍼큐브에 대한 작업을 수행하는 것이 가능합니다.
3. OLAP 기술 창조의 역사
다차원 배열에서 데이터를 처리한다는 아이디어는 새로운 것이 아닙니다. 사실, Ken Iverson이 그의 책 APL(프로그래밍 언어)을 출판한 1962년으로 거슬러 올라갑니다. APL의 첫 번째 실제 구현은 60년대 후반 IBM에 의해 이루어졌습니다. APL은 다차원 변수와 처리된 연산이 있는 매우 우아하고 수학적으로 정의된 언어입니다. 다른 실용적인 프로그래밍 언어와 비교하여 다차원 변환 작업을 위한 원래의 강력한 도구를 의도했습니다.
그러나 그래픽 인터페이스, 고품질 인쇄 장치 및 그리스 문자 표시에는 특수 화면, 키보드 및 인쇄 장치가 필요한 시대가 아직 오지 않았기 때문에 아이디어는 오랫동안 대중적인 응용을 받지 못했습니다. 나중에 영어 단어가 그리스어 연산자를 대체하는 데 때때로 사용되었지만 APL 순결 전사는 그들이 가장 좋아하는 언어를 대중화하려는 시도를 방해했습니다. APL은 또한 기계 자원을 소비했습니다. 그 당시에는 비용이 많이 들었습니다. 프로그램 실행 속도가 매우 느리고 실행 비용도 매우 비쌌습니다. 당시에는 엄청난 양(약 6MB)에 불과한 많은 메모리가 필요했습니다.
그러나 이러한 초기 실수의 성가심은 아이디어를 죽이지 못했습니다. 70년대와 80년대에 많은 비즈니스 애플리케이션에서 사용되었습니다. 이러한 응용 프로그램 중 많은 기능이 현대 시스템분석 처리. 예를 들어 IBM이 개발한 운영 체제 VSPC라고 하는 APL용으로 일부 사람들은 스프레드시트가 유비쿼터스되기 전까지 개인용으로 이상적인 매체라고 생각했습니다.
그러나 APL은 사용하기가 너무 어려웠습니다. 특히 언어 자체와 구현을 시도한 하드웨어 간에 불일치가 발생할 때마다 특히 그렇습니다.
1980년대에 APL은 개인용 컴퓨터에서 사용할 수 있게 되었지만 시장에서 사용되지는 않았습니다. 대안은 다른 언어의 배열을 사용하여 다차원 응용 프로그램을 프로그래밍하는 것이었습니다. 이것은 전문 프로그래머에게도 매우 어려운 작업이었고, 이로 인해 차세대 다차원 소프트웨어 제품을 기다려야 했습니다.
1972년에 교육 목적으로 이전에 사용되었던 여러 다차원 소프트웨어 응용 프로그램이 상업용으로 발견되었습니다. Express. 그것은 지금도 완전히 재작성된 형태로 남아 있지만, 70년대의 원래 개념은 더 이상 관련이 없습니다. 오늘날, 90년대에 Express는 가장 인기 있는 OLAP 기술 중 하나이며 Oracle(r)은 계속해서 이를 추진하고 새로운 기능을 추가할 것입니다.
80년대에는 더 다차원적인 제품이 등장했습니다. 10년 초반에 Stratagem이라는 제품이 나중에 Acumate(현재 Kenan Technologies 소유)라고 불리며 90년대 초반까지 계속 홍보되었지만 오늘날에는 Express와 달리 실제로 사용되지 않습니다.
Comshare System W는 다른 스타일의 다차원 제품이었습니다. 1981년에 도입된 이 제품은 최종 사용자와 금융 애플리케이션 개발에 더 중점을 둔 최초의 제품입니다. 완전히 비절차적 규칙, 다차원 데이터의 전체 화면 보기 및 편집, 자동 재계산 및 관계형 데이터와의 일괄 통합과 같이 잘 적용되지 않은 많은 개념을 도입했습니다. 그러나 Comshare System W는 다른 제품들에 비해 당시의 하드웨어에 비해 상당히 무거웠고, 미래에는 덜 사용되었고 덜 팔렸고 제품에 대한 개선도 이루어지지 않았습니다. 오늘날에도 여전히 UNIX에서 사용할 수 있지만 클라이언트-서버가 아니므로 분석 제품 시장에서 제공하는 제품을 늘리는 데 도움이 되지 않습니다. 80년대 후반에 Comshare는 DOS용 제품과 나중에 Windows용 제품을 출시했습니다. 이 제품들은 Commander Prism이라고 불리며 System W와 같은 개념을 사용했습니다.
80년대 후반의 또 다른 창의적인 제품은 Metaphor라고 불렸습니다. 전문 마케터를 위한 것이었습니다. 그는 또한 클라이언트-서버 컴퓨팅, 관계형 데이터에 대한 다차원 모델의 사용, 객체 지향 응용 프로그램 개발과 같이 이제 막 널리 사용되기 시작한 많은 새로운 개념을 제안했습니다. 그러나 당시의 표준 PC 하드웨어는 Metaphor를 실행할 수 없었고 공급업체는 PC 및 네트워크에 대한 자체 표준을 개발해야 했습니다. 점차적으로 Metaphor는 직렬 개인용 컴퓨터에서 성공적으로 작동하기 시작했지만 제품은 OS/2 전용으로 만들어졌으며 자체 그래픽 사용자 인터페이스가 있었습니다.
그런 다음 Metaphor는 IBM과 마케팅 제휴를 맺었고 이후 흡수되었습니다. 1994년 중반 IBM은 Metaphor 기술(DIS로 개명)을 미래 기술과 통합하여 별도의 자금 조달을 중단하기로 결정했지만 고객은 불만을 표시하고 제품에 대한 지속적인 지원을 요구했습니다. 나머지 고객에 대한 지원은 계속되었고 IBM은 DIS라는 새 이름으로 제품을 다시 출시했지만 인기를 얻지는 못했습니다. 그러나 Metaphor의 창의적이고 혁신적인 개념은 잊혀지지 않았고 오늘날 많은 제품에서 볼 수 있습니다.
80년대 중반 EIS(Executive Information System)라는 용어가 탄생했습니다. 이 방향을 명확하게 보여주는 첫 번째 제품은 파일럿 사령부였습니다. 그것은 오늘날 우리가 클라이언트-서버 컴퓨팅이라고 부르는 협업 컴퓨팅을 가능하게 하는 제품이었습니다. 80년대 개인용 컴퓨터의 힘은 제한적이었으므로 제품은 매우 "서버 중심적"이었지만 이 원칙은 오늘날에도 여전히 매우 인기가 있습니다. Pilot은 오랫동안 Command Center를 판매하지 않았지만 자동 타이밍 지원, 다차원 클라이언트-서버 컴퓨팅 및 단순화된 분석 프로세스 제어(마우스, 민감한 화면 등)를 포함하여 오늘날의 OLAP 제품에서 인식할 수 있는 많은 개념을 제공했습니다. ). 이러한 개념 중 일부는 나중에 Pilot Analysis Server에서 다시 적용되었습니다.
1980년대 후반에 스프레드시트는 최종 사용자를 위한 분석 도구 시장을 지배했습니다. 최초의 다차원 스프레드시트는 Compet 제품에 의해 도입되었습니다. 이 제품은 전문가용으로 매우 비싼 제품으로 판매되었지만 공급업체는 제품이 시장을 장악할 수 있는지 확인하지 못했고 Computer Associates는 Supercalc 및 20/20을 비롯한 다른 제품과 함께 이 제품에 대한 권리를 획득했습니다. CA Compete 인수의 주요 효과는 가격의 급격한 하락과 복제 방지의 제거였으며 자연스럽게 배포에 기여했습니다. 그러나 그는 성공하지 못했습니다. 경쟁은 Supercalc 5의 핵심이지만 다차원적 측면은 홍보되지 않습니다. 한 번에 많은 돈이 투자되었다는 사실 때문에 오래된 경쟁이 여전히 때때로 사용됩니다.
다음으로 Lotus는 NeXT 머신에서 실행되는 Improv 제품으로 다차원 스프레드시트 시장에 진입하려고 했습니다. 이것은 최소한 1-2-3의 판매가 떨어지지 않도록 보장했지만 결국 Windows용으로 출시되었을 때 Excel은 이미 큰 시장 점유율을 차지하여 Lotus가 시장 배포를 변경할 수 없었습니다. Lotus는 Compete가 있는 CA와 마찬가지로 Improv를 시장의 바닥으로 옮겼지만 이것이 시장에서 성공적인 판촉의 조건이 되지 않았고 이 분야의 새로운 개발이 계속되지 않았습니다. 개인용 컴퓨터 사용자는 1-2-3 스프레드시트를 선호하고 기존 스프레드시트와 완전히 호환되지 않는 한 새로운 다차원 기능에 관심이 없는 것으로 나타났습니다. 마찬가지로 개인 응용 프로그램으로 제공되는 작은 데스크톱 스프레드시트의 개념은 실제로 편리하다는 것이 입증되지 않았으며 실제 비즈니스 세계에 적용되지 않았습니다. Microsoft(r)는 Excel에 피벗 테이블을 추가하여 이 경로를 밟았습니다. 이 기능을 사용하는 Excel 사용자는 거의 없지만 전 세계에 Excel 사용자가 너무 많기 때문에 다변량 분석 기능이 전 세계적으로 널리 사용되는 유일한 사실일 것입니다.
4. OLAP, ROLAP, MOLAP…
Codd가 1985년 관계형 DBMS 구축에 대한 자신의 규칙을 발표했을 때 강력한 반향을 일으켰고 이후 DBMS 산업 전반에 큰 영향을 미쳤다는 것은 잘 알려져 있습니다. 그러나 1993년 Codd가 "분석 사용자를 위한 OLAP: What It Should Be"라는 작업을 출판했다는 사실을 아는 사람은 거의 없습니다. 그 책에서 그는 온라인 분석 처리의 기본 개념을 설명하고 제품이 온라인 분석 처리를 제공하기 위해 충족해야 하는 12가지 규칙을 식별했습니다.
다음은 규칙입니다(가능한 경우 원본 텍스트가 유지됨).
1. 개념적 다차원 표현. 분석가 사용자는 엔터프라이즈 세계를 본질적으로 다차원으로 봅니다. 따라서 OLAP 모델은 기본적으로 다차원적이어야 합니다. 다차원 개념 다이어그램 또는 사용자 정의 표현은 계산뿐 아니라 모델링 및 분석을 용이하게 합니다.
2. 투명성. OLAP 제품이 사용자 도구의 일부인지 여부에 관계없이 이 사실은 사용자에게 투명해야 합니다. OLAP가 클라이언트-서버 컴퓨팅에 의해 제공되는 경우 이 사실은 가능하다면 사용자에게도 보이지 않아야 합니다. OLAP는 사용자가 어디에 있든 분석 도구를 사용하여 서버와 통신할 수 있도록 하는 진정한 개방형 아키텍처의 컨텍스트에서 제공되어야 합니다. 또한 분석 도구가 동종 및 이종 데이터베이스 환경과 상호 작용할 때 투명성도 확보해야 합니다.
3. 가용성. OLAP 분석가 사용자는 관계형 데이터베이스의 전사적 데이터와 레거시 레거시 데이터베이스의 데이터, 공통 액세스 방법 및 공통 분석 모델을 포함하는 공통 개념 스키마를 기반으로 분석을 수행할 수 있어야 합니다. 즉, OLAP는 이기종 데이터베이스 환경에서 액세스하기 위한 자체 논리를 제공하고 적절한 변환을 수행하여 사용자에게 데이터를 제공해야 합니다. 또한 물리적 데이터 조직이 실제로 어디에, 어떻게, 어떤 형태로 사용될 것인지에 대한 사전 주의가 필요하다. OLAP 시스템은 실제로 필요한 데이터에만 액세스해야 하며 적용해서는 안 됩니다. 일반 원칙불필요한 입력을 수반하는 "주방 깔때기".
4. 보고서 개발의 일관된 생산성. 차원의 수나 데이터베이스의 크기가 증가하더라도 분석가 사용자는 성능이 크게 저하되지 않아야 합니다. 일관된 성능은 최종 사용자의 사용 편의성을 유지하고 OLAP 복잡성을 제한하는 데 매우 중요합니다. 분석가 사용자가 차원의 수에 따라 성능에서 상당한 차이를 경험하는 경우 분석가는 이러한 차이를 개발 전략으로 보상하는 경향이 있으며, 이는 데이터가 실제로 필요한 방식과 다른 방식으로 데이터를 표시하게 합니다. 제시된다. 시스템의 부적절함을 보완하기 위해 시스템을 우회하여 시간을 낭비하는 것은 분석 제품이 설계된 목적이 아닙니다.
5. 클라이언트-서버 아키텍처. 오늘날 온라인 분석에 필요한 대부분의 데이터는 PC를 통해 액세스되는 메인프레임에 있습니다. 따라서 OLAP 제품은 클라이언트-서버 환경에서 작동할 수 있어야 합니다. 이러한 관점에서 분석 도구의 서버 구성 요소는 실질적으로 "스마트"해야 합니다. 다양한 클라이언트최소한의 번거로움과 통합 프로그래밍으로 서버에 참여할 수 있습니다. "지능형" 서버는 부적절한 논리적 및 물리적 데이터베이스 스키마를 매핑하고 통합할 수 있어야 합니다. 이것은 투명성과 공통의 개념적, 논리적, 물리적 체계의 구성을 보장할 것입니다.
6. 일반적인 다차원성. 각 차원은 구조 및 운영 능력에 관계없이 적용되어야 합니다. 선택된 차원에 추가적인 운용 능력을 부여할 수 있으며, 차원이 대칭적이기 때문에 모든 차원에 하나의 기능을 부여할 수 있다. 기본 데이터 구조, 수식 및 보고 형식은 어떤 차원에도 편향되어서는 안 됩니다.
7. 희소 행렬의 동적 제어. OLAP 도구의 물리적 설계는 희소 행렬을 최적으로 관리하기 위해 특정 분석 모델에 완전히 적응할 수 있어야 합니다. 주어진 희소 행렬에 대해 최적의 물리적 체계는 단 하나뿐입니다. 이 방식은 물론 전체 데이터 세트가 메모리에 맞지 않는 한 최대 메모리 효율성과 매트릭스 운용성을 제공합니다. OLAP 도구의 기본 물리적 데이터는 대규모 분석 모델을 사용한 실제 작업을 위해 순서에 관계없이 차원의 모든 하위 집합으로 구성되어야 합니다. 물리적 액세스 방법도 동적으로 변경되어야 하며 직접 계산, B-트리 및 파생 상품, 해싱, 필요한 경우 이러한 메커니즘을 결합하는 기능과 같은 다양한 유형의 메커니즘을 포함해야 합니다. 희소성(가능한 모든 셀에 대한 빈 셀의 백분율로 측정)은 데이터 전파의 특성 중 하나입니다. 희소성을 제어할 수 없으면 작업의 효율성을 달성할 수 없습니다. OLAP 도구가 분석된 데이터 값의 분포를 제어하고 규제할 수 없는 경우 많은 통합 경로와 차원을 기반으로 실용적이라고 주장하는 모델은 실제로 불필요하고 희망이 없을 수 있습니다.
8. 다중 사용자 지원. 종종 여러 분석가 사용자가 동일한 분석 모델에서 함께 작업하거나 동일한 데이터에서 다른 모델을 만들어야 합니다. 따라서 OLAP 도구는 공유(쿼리 및 추가), 무결성 및 보안 기능을 제공해야 합니다.
9. 무제한 교차 작업. 계층적 특성으로 인해 서로 다른 롤업 수준 및 통합 경로는 OLAP 모델 또는 응용 프로그램에서 종속 관계를 나타냅니다. 따라서 도구 자체는 적절한 계산을 암시해야 하며 분석가 사용자가 이러한 계산 및 작업을 재정의할 것을 요구하지 않아야 합니다. 이러한 상속된 관계에서 따르지 않는 계산은 일부 적용 가능한 언어에 따라 다른 공식으로 정의해야 합니다. 이러한 언어는 모든 차원의 데이터로 계산 및 조작을 허용할 수 있으며 데이터 셀 간의 관계를 제한하지 않으며 특정 셀의 공통 데이터 속성 수에 주의를 기울이지 않습니다.
10. 직관적인 데이터 조작. 통합 경로의 방향 변경, 상세화, 확대 및 통합 경로에 의해 규제되는 기타 조작은 분석 모델의 셀에 대한 별도의 작업을 통해 적용해야 하며 메뉴 시스템 또는 사용자 인터페이스. 분석 모델에 정의된 차원에 대한 분석가 사용자의 보기에는 위의 작업을 수행하는 데 필요한 모든 정보가 포함되어야 합니다.
11. 유연한 보고 옵션. 시각적으로 서로 비교할 데이터의 행, 열 및 셀이 서로 가깝거나 기업에서 발생하는 일부 논리적 기능에 따라 데이터의 분석 및 표시가 간단합니다. 보고 도구는 가능한 모든 방향에서 데이터 모델에서 생성된 합성 데이터 또는 정보를 나타내야 합니다. 이는 행, 열 또는 페이지가 0에서 N 차원까지 동시에 표시되어야 함을 의미합니다. 여기서 N은 전체 분석 모델의 차원 수입니다. 또한 단일 레코드, 열 또는 페이지에 표시되는 각 콘텐츠 차원은 차원에 포함된 요소(값)의 하위 집합을 임의의 순서로 표시할 수도 있어야 합니다.
12. 무제한 차원 및 집계 수준 수. 해석 모델에 필요한 필요한 측정의 가능한 수에 대한 연구에 따르면 최대 19개의 측정을 동시에 사용할 수 있습니다. 따라서 분석 도구는 동시에 최소 15개의 차원을 제공할 수 있고 바람직하게는 20개의 차원을 제공할 수 있도록 강력히 권장됩니다. 또한 각 공통 차원은 분석 사용자가 정의한 집계 수준 및 통합 경로의 수로 제한되어서는 안 됩니다.
사실, 오늘날 OLAP 제품 개발자는 이러한 규칙을 따르거나 최소한 따르기 위해 노력합니다. 이러한 규칙은 운영 분석 처리의 이론적 기초로 간주될 수 있으며 이에 대해 논쟁하기가 어렵습니다. 그 후 12가지 규칙에서 많은 결과가 도출되었지만 이야기를 불필요하게 복잡하게 만들지 않기 위해 제공하지는 않습니다.
OLAP 제품의 물리적 구현이 어떻게 다른지 자세히 살펴보겠습니다.
위에서 언급했듯이 OLAP는 다차원 구조에서 데이터를 처리한다는 아이디어를 기반으로 합니다. OLAP라고 하면 논리적으로 분석 제품의 데이터 구조가 다차원적이라는 의미입니다. 그것을 구현하는 방법은 또 다른 문제입니다. 특정 제품을 포함하는 분석 처리에는 두 가지 주요 유형이 있습니다.
몰랍 . 실제로 다차원(다차원) OLAP. 이 제품은 데이터의 다차원 저장, 처리 및 표시를 제공하는 비관계형 데이터 구조를 기반으로 합니다. 따라서 데이터베이스를 다차원이라고도 합니다. 이 클래스의 제품에는 일반적으로 다차원 데이터베이스 서버가 있습니다. 분석 프로세스의 데이터는 다차원 구조에서 독점적으로 선택됩니다. 이러한 구조는 매우 생산적입니다.
롤랩 . 관계형 OLAP. 이름에서 알 수 있듯이 이러한 도구의 다차원 구조는 관계형 테이블로 구현됩니다. 그리고 분석 프로세스의 데이터는 각각 분석 도구에 의해 관계형 데이터베이스에서 선택됩니다.
일반적으로 각 접근 방식의 단점과 장점은 분명합니다. 다차원 OLAP 제공 더 나은 성능, 그러나 구조는 많은 양의 데이터를 처리하는 데 사용할 수 없습니다. 큰 차원은 큰 하드웨어 리소스를 필요로 하고 동시에 하이퍼큐브의 희소성이 매우 높을 수 있으므로 하드웨어 용량의 사용은 정당화. 이에 반해 관계형 OLAP는 대용량의 저장된 데이터에 대한 처리를 제공하는데, 그 이유는 보다 경제적인 스토리지를 제공할 수 있기 때문이지만 동시에 다차원 OLAP의 속도에서 크게 떨어집니다. 이러한 추론은 새로운 종류의 분석 도구인 HOLAP을 선택하게 했습니다. 이것은 하이브리드(하이브리드) 운영 분석 처리입니다. 이 클래스의 도구를 사용하면 관계형 및 다차원적 접근 방식을 모두 결합할 수 있습니다. 다차원 데이터베이스의 데이터와 관계형 데이터 모두에 액세스할 수 있습니다.
또 다른 다소 이국적인 유형의 온라인 분석 처리인 DOLAP이 있습니다. 이것은 "데스크탑" OLAP입니다. 우리는 하이퍼 큐브가 작고 치수가 작고 요구 사항이 적당하며 이러한 분석 처리를 위해서는 데스크탑의 개인용 컴퓨터로 충분하다는 분석 처리에 대해 이야기하고 있습니다.
운영 분석 처리는 관리 직원이 준비하고 결정을 내리는 프로세스를 크게 단순화하고 가속화할 수 있습니다. 온라인 분석 처리는 데이터를 정보로 전환하는 목적을 제공합니다. 이는 대부분 구조화된 보고서를 고려하는 기존의 의사 결정 지원 프로세스와 근본적으로 다릅니다. 유추해 보면 구조화된 보고서와 OLAP의 차이점은 트램과 자동차로 도시를 운전하는 것과 같습니다. 트램을 타면 레일을 따라 움직이기 때문에 멀리 있는 건물이 잘 보이지 않고 가까이 다가가기가 훨씬 어렵습니다. 반대로 자가용을 운전하면 완전한 이동이 가능합니다(물론 교통 규칙을 준수해야 함). 아무 건물까지 차를 몰고 트램이 다니지 않는 곳까지 갈 수 있습니다.
구조화된 보고서는 의사 결정의 자유를 가로막는 레일입니다. OLAP은 정보 고속도로에서 효율적인 이동을 위한 자동차입니다.
온라인 분석 처리(OLAP)는 모든 종류의 데이터의 거대한 배열을 기반으로 요약 정보를 생성하는 효율적인 데이터 처리 기술입니다. PC에 있는 정보에 접근하고, 추출하고, 보고, 다양한 관점에서 분석할 수 있도록 도와주는 강력한 제품입니다.
OLAP은 장기 계획을 위한 전략적 위치를 제공하고 5년, 10년 또는 그 이상의 기간 동안 운영 데이터의 기본 정보를 고려하는 도구입니다. 데이터는 속성인 차원과 함께 데이터베이스에 저장됩니다. 사용자는 분석 목적에 따라 다른 속성을 가진 동일한 데이터 세트를 볼 수 있습니다.
OLAP의 역사
OLAP는 새로운 개념이 아니며 수십 년 동안 사용되어 왔습니다. 사실 이 기술의 기원은 1962년으로 거슬러 올라갑니다. 그러나 이 용어는 1993년에 데이터베이스 작성자인 Ted Codd에 의해 만들어졌습니다. Ted Codd는 제품에 대한 12가지 규칙도 제정했습니다. 다른 많은 응용 프로그램과 마찬가지로 이 개념은 여러 단계의 진화를 거쳤습니다.
OLAP 기술 자체의 역사는 Express 정보 리소스와 최초의 Olap 서버가 출시된 1970년으로 거슬러 올라갑니다. 그들은 1995년에 Oracle에 인수되었으며 이후 잘 알려진 컴퓨터 브랜드가 데이터베이스에 제공한 다차원 컴퓨팅 엔진의 온라인 분석 처리의 기초가 되었습니다. 1992년에는 또 다른 유명한 온라인 분석 처리 제품인 Essbase가 Arbor Software(2007년 Oracle에 인수됨)에서 출시되었습니다.
1998년 Microsoft는 온라인 분석 데이터 처리 서버인 MS Analysis Services를 출시했습니다. 이것은 기술의 인기에 기여했고 다른 제품 개발에 박차를 가했습니다. 오늘날 IBM, SAS, SAP, Essbase, Microsoft, Oracle, IcCube를 포함하여 Olap 애플리케이션을 제공하는 세계적으로 유명한 여러 공급업체가 있습니다.
온라인 분석 처리
OLAP는 예정된 이벤트에 대한 결정을 내릴 수 있는 도구입니다. 비정형 Olap 계산은 단순한 데이터 집계보다 더 복잡할 수 있습니다. 분당 분석 요청(AQM)은 다양한 기기의 성능을 비교하기 위한 표준 벤치마크로 사용됩니다. 이러한 시스템은 복잡한 쿼리 구문에서 가능한 한 사용자를 숨겨야 하고 모든 사람에게 일관된 응답 시간을 제공해야 합니다(복잡한 사용자가 상관없이).
OLAP의 주요 특징은 다음과 같습니다.
- 데이터의 다차원 표현.
- 복잡한 계산을 지원합니다.
- 임시 지능.
다차원 보기는 기업 데이터에 대한 유연한 액세스를 통해 분석 처리의 기반을 제공합니다. 이를 통해 사용자는 모든 차원과 집계 수준에서 데이터를 분석할 수 있습니다.
복잡한 계산에 대한 지원은 OLAP 소프트웨어의 백본입니다.
시간 인텔리전스는 모든 작업의 효율성을 평가하는 데 사용됩니다. 분석적 응용일정 기간 동안. 예를 들어 이번 달은 지난 달과 비교하고 이번 달은 작년 같은 달과 비교합니다.
다차원 데이터 구조
온라인 분석 처리의 주요 특징 중 하나는 다차원 데이터 구조입니다. 큐브는 여러 차원을 가질 수 있습니다. 이 모델 덕분에 셀에 표시된 개체가 실제 비즈니스 개체이기 때문에 지능형 OLAP 분석의 전체 프로세스는 관리자와 경영진에게 간단합니다. 또한, 이 데이터 모델을 통해 사용자는 정형 배열뿐만 아니라 비정형 및 반정형 배열도 처리할 수 있습니다. 이 모든 것이 데이터 분석 및 BI 응용 프로그램에 특히 인기가 있습니다.

OLAP 시스템의 주요 특징:
- 데이터 분석의 다차원 방법을 사용합니다.
- 확장된 데이터베이스 지원을 제공합니다.
- 사용하기 쉬운 최종 사용자 인터페이스를 만듭니다.
- 클라이언트/서버 아키텍처를 지원합니다.
OLAP 개념의 주요 구성 요소 중 하나는 클라이언트 측 서버입니다. 집계 및 전처리관계형 데이터베이스의 데이터를 사용하여 고급 계산 및 기록 옵션, 추가 기능, 기본 고급 쿼리 기능 및 기타 기능을 제공합니다.
사용자가 선택한 샘플 애플리케이션에 따라 실시간 경고, 가상 시나리오 적용 기능, 최적화, 정교한 OLAP 보고서 등 다양한 데이터 모델과 도구를 사용할 수 있습니다.
입방체
이 개념은 입방체 모양을 기반으로 합니다. 그 안의 데이터 레이아웃은 OLAP가 다차원 분석 원칙을 어떻게 준수하는지 보여주므로 빠르고 효율적인 분석을 위해 설계된 데이터 구조가 만들어집니다.
OLAP 큐브는 "하이퍼큐브"라고도 합니다. 패싯(dimensions)으로 분류된 수치적 사실(measures)로 구성된 것으로 설명된다. 차원은 비즈니스 문제를 정의하는 속성을 나타냅니다. 간단히 말해서 차원은 측정값을 설명하는 레이블입니다. 예를 들어 판매 보고서에서 측정값은 판매량이고 차원에는 판매 기간, 영업 사원, 제품 또는 서비스, 판매 지역이 포함됩니다. 제조 작업에 대한 보고에서 측정값은 총 제조 비용과 산출 단위가 될 수 있습니다. 차원은 생산 날짜 또는 시간, 생산 단계 또는 단계, 심지어 생산 공정에 관련된 작업자가 될 것입니다.

OLAP 데이터 큐브는 시스템의 초석입니다. 큐브의 데이터는 별 또는 눈송이 구성표를 사용하여 구성됩니다. 중앙에는 집계(측정값)가 포함된 팩트 테이블이 있습니다. 측정값에 대한 정보가 포함된 일련의 차원 테이블에 연결됩니다. 차원은 이러한 측정값을 분석하는 방법을 설명합니다. 정육면체에 3차원 이상이 포함된 경우 이를 하이퍼큐브라고 합니다.
큐브에 속하는 주요 기능 중 하나는 정적인 특성으로 큐브가 디자인된 후에는 변경할 수 없음을 의미합니다. 따라서 큐브를 만들고 데이터 모델을 설정하는 프로세스는 OLAP 아키텍처에서 적절한 데이터 처리를 위한 중요한 단계입니다.
데이터 집계
집계 사용은 쿼리가 OLAP 도구(OLTP에 비해)에서 훨씬 빠르게 처리되는 주된 이유입니다. 집계는 처리 당시 미리 계산된 데이터의 요약입니다. OLAP 차원 테이블에 저장된 모든 멤버는 큐브가 수신할 수 있는 쿼리를 정의합니다.
큐브에서 정보 누적은 셀에 저장되며 좌표는 특정 크기로 지정됩니다. 큐브에 포함될 수 있는 집계 수는 가능한 모든 차원 구성원 조합에 따라 다릅니다. 따라서 응용 프로그램의 일반적인 큐브에는 매우 많은 수의 집계가 포함될 수 있습니다. 사전 계산은 온라인 분석 분석 큐브 전체에 분산된 주요 집계에 대해서만 수행됩니다. 이렇게 하면 데이터 모델에서 쿼리를 실행할 때 집계를 정의하는 데 걸리는 시간이 크게 줄어듭니다.
완성된 큐브의 성능을 개선하는 데 사용할 수 있는 두 가지 집계 관련 옵션도 있습니다. 기능 캐시 집계를 만들고 사용자 쿼리 분석을 기반으로 집계를 사용합니다.
작동 원리
일반적으로 거래에서 파생된 운영 정보의 분석은 간단한 스프레드시트를 사용하여 수행할 수 있습니다(데이터 값은 행과 열로 표시됨). 이는 데이터의 2차원 특성을 고려할 때 좋습니다. OLAP의 경우 다차원 데이터 배열과 관련된 차이점이 있습니다. 종종 다른 소스에서 가져오기 때문에 스프레드시트에서 항상 효율적으로 처리할 수는 없습니다.
큐브는 이 문제를 해결하고 논리적이고 질서 있는 방식으로 OLAP 데이터 웨어하우스를 계속 실행합니다. 비즈니스는 수많은 소스에서 데이터를 수집하고 다음과 같은 다양한 형식으로 제공됩니다. 텍스트 파일, 멀티미디어 파일, Excel 스프레드시트, 데이터베이스 데이터 액세스 OLTP 데이터베이스도 있습니다.

모든 데이터는 소스에서 직접 채워진 저장소에 수집됩니다. 여기에는 OLTP 및 기타 소스에서 받은 원시 정보가 오류, 불완전 및 일관성 없는 트랜잭션에서 지워집니다.
정리 및 변환 후 정보는 관계형 데이터베이스에 저장됩니다. 그런 다음 분석을 위해 다차원 OLAP 서버(또는 Olap 큐브)에 업로드됩니다. 비즈니스 애플리케이션, 데이터 마이닝 및 기타 비즈니스 운영을 담당하는 최종 사용자는 Olap 큐브에서 필요한 정보에 액세스할 수 있습니다.
어레이 모델의 이점
OLAP은 시스템의 큰 장점 중 하나인 최적화된 스토리지, 다차원 인덱싱 및 캐싱을 통해 빠른 쿼리 성능을 제공하는 도구입니다. 또한 이점은 다음과 같습니다.
- 디스크의 데이터 크기가 작습니다.
- 더 높은 수준의 데이터 집계 자동 계산.
- 배열 모델은 자연스러운 인덱싱을 제공합니다.
- 사전 구조화를 통해 효율적인 데이터 추출이 이루어집니다.
- 저차원 데이터셋을 위한 압축성.
OLAP의 단점은 특히 많은 양의 정보가 있는 경우 일부 결정(처리 단계)이 상당히 길 수 있다는 사실을 포함합니다. 이것은 일반적으로 증분 처리(변경된 데이터 검사)만 수행하여 수정됩니다.
기본 분석 작업
회선(롤업/드릴업)은 "통합"이라고도 합니다. 접기에는 얻을 수 있는 모든 데이터를 수집하고 하나 이상의 차원에서 모두 계산하는 작업이 포함됩니다. 대부분의 경우 수학 공식을 적용해야 할 수 있습니다. OLAP의 예로 여러 도시에 매장이 있는 소매 체인을 생각해 보십시오. 패턴을 식별하고 향후 판매 동향을 예측하기 위해 통합 및 계산을 위해 모든 위치에서 회사의 주요 영업 부서로 패턴을 롤업합니다.
폭로(드릴다운). 이것은 접는 것과 반대입니다. 프로세스는 큰 데이터 세트로 시작한 다음 더 작은 조각으로 분해하여 사용자가 세부 정보를 볼 수 있도록 합니다. 소매 체인 예에서 분석가는 판매 데이터를 분석하고 서로 다른 도시의 각 매장에서 베스트 셀러로 간주되는 개별 브랜드 또는 제품을 살펴봅니다.

교차 구역(슬라이스 및 주사위). 이는 분석 작업에 OLAP 큐브(분석의 "분할" 측면)에서 특정 데이터 집합을 추출하고 다른 관점이나 각도에서 보는 두 가지 작업이 포함되는 프로세스입니다. 이것은 모든 콘센트 데이터가 수신되어 하이퍼큐브에 입력되었을 때 발생할 수 있습니다. 분석가는 OLAP Cube에서 판매와 관련된 데이터 세트를 잘라냅니다. 추후 지역별 개별 유닛 판매를 분석할 때 검토할 예정이다. 이때, 다른 사용자는 판매의 비용 효율성을 평가하거나 마케팅 및 광고 캠페인의 효율성을 평가하는 데 집중할 수 있습니다.
회전하다(피벗). 정보의 대체 표현을 제공하기 위해 데이터 축을 회전합니다.
데이터베이스 품종
기본적으로 이것은 분석 프로세스가 필요에 따라 차원을 추가할 수 있도록 OLAP Cube 또는 모든 데이터 큐브로 다차원 데이터 분석을 구현하는 일반적인 OLAP 큐브입니다. 다차원 데이터베이스에 로드된 모든 정보는 저장되거나 보관되며 필요할 때 불러올 수 있습니다.
| 의미 |
|
| 관계형 OLAP(ROLAP) | ROLAP은 표준 관계형 연산을 수행하기 위해 다차원 데이터 매핑과 함께 고급 DBMS입니다. |
| 다차원 OLAP(MOLAP) | MOLAP - 다차원 데이터 작업 구현 |
| HOLAP(하이브리드 온라인 분석 처리) | HOLAP 접근 방식에서 집계된 합계는 다차원 데이터베이스에 저장되고 자세한 정보는 관계형 데이터베이스에 저장됩니다. 이것은 ROLAP 모델의 효율성과 MOLAP 모델의 성능을 모두 보장합니다. |
| OLAP 데스크탑(DOLAP) | Desktop OLAP에서 사용자는 데이터베이스에서 로컬로 또는 데스크톱으로 데이터를 다운로드하여 분석합니다. DOLAP은 제공하는 것이 거의 없기 때문에 배포 비용이 상대적으로 저렴합니다. 기능다른 OLAP 시스템에 비해 |
| 웹 OLAP(WOLAP) | 웹 OLAP은 웹 브라우저를 통해 액세스할 수 있는 OLAP 시스템입니다. WOLAP은 3계층 아키텍처입니다. 클라이언트, 중간의 세 가지 구성 요소로 구성됩니다. 소프트웨어및 데이터베이스 서버 |
| 모바일 OLAP | 모바일 OLAP는 사용자가 자신의 데이터를 사용하여 OLAP 데이터에 액세스하고 분석할 수 있도록 모바일 기기 |
| 공간 OLAP | SOLAP은 지리 정보 시스템(GIS)에서 공간 및 비공간 데이터의 관리를 용이하게 하기 위해 만들어졌습니다. |
덜 알려진 OLAP 시스템이나 기술이 있지만 이들은 현재 대기업, 기업, 심지어 정부에서 사용하는 주요 시스템입니다.

OLAP 도구
온라인 분석 처리 도구는 유료 버전과 무료 버전 모두에서 인터넷에 잘 알려져 있습니다.
그 중 가장 인기 있는 것:
- Dundas Data Visualization의 Dundas BI는 통합 대시보드, OLAP 보고 도구 및 데이터 분석을 포함하는 브라우저 기반 비즈니스 인텔리전스 및 데이터 시각화 플랫폼입니다.
- Yellowfin은 다양한 산업 및 규모의 기업을 위해 설계된 단일 통합 솔루션인 비즈니스 인텔리전스 플랫폼입니다. 이 시스템은 회계, 광고, 농업 분야의 비즈니스에 맞게 사용자 정의할 수 있습니다.
- ClicData는 주로 중소기업에서 사용하도록 설계된 비즈니스 인텔리전스(BI) 솔루션입니다. 이 도구를 사용하면 최종 사용자가 보고서와 대시보드를 만들 수 있습니다. 보드는 비즈니스 인텔리전스, 엔터프라이즈 성능 관리를 결합하기 위해 만들어졌으며 중간 규모 및 기업 수준.
- Domo는 스프레드시트, 데이터베이스, 소셜 네트워크기존 클라우드 또는 로컬 소프트웨어 솔루션.
- InetSoft Style Intelligence는 사용자가 매시업 엔진을 사용하여 대시보드, OLAP 시각적 분석 기술 및 보고서를 생성할 수 있는 비즈니스 분석 소프트웨어 플랫폼입니다.
- Infor Company의 Birst는 정보에 입각한 결정을 내리는 데 도움이 되도록 팀 전체에 통찰력을 연결하는 웹 기반 비즈니스 인텔리전스 및 분석 솔루션입니다. 이 도구를 사용하면 분산된 사용자가 엔터프라이즈 팀 모델을 확장할 수 있습니다.
- Halo는 공급망 관리를 위한 비즈니스 계획 및 재고 예측을 지원하는 포괄적인 공급망 관리 및 비즈니스 인텔리전스 시스템입니다. 시스템은 모든 소스의 데이터(대형, 소형 및 중형)를 사용합니다.
- Chartio는 창업자, 비즈니스 팀, 데이터 분석가 및 제품 팀에 일상 업무를 구성하는 도구를 제공하는 클라우드 기반 비즈니스 분석 솔루션입니다.
- Exago BI는 웹 애플리케이션에 내장되도록 설계된 웹 솔루션입니다. Exago BI를 구현하면 모든 규모의 기업이 고객에게 임시, 실시간 및 대화형 보고를 제공할 수 있습니다.
비즈니스 영향
사용자는 산업 전반에 걸쳐 대부분의 비즈니스 응용 프로그램에서 OLAP를 찾을 수 있습니다. 분석은 비즈니스뿐만 아니라 다른 이해 관계자도 사용합니다.

가장 일반적인 응용 프로그램은 다음과 같습니다.
- 마케팅 OLAP 데이터 분석.
- 판매 및 비용, 예산 및 재무 계획을 다루는 재무 보고.
- 비즈니스 프로세스 관리.
- 판매 분석.
- 데이터베이스 마케팅.
산업은 계속해서 성장하고 있으며, 이는 곧 사용자가 더 많은 OLAP 응용 프로그램을 볼 수 있음을 의미합니다. 다변수 맞춤형 처리는 보다 동적인 분석을 제공합니다. 이러한 OLAP 시스템 및 기술을 사용하여 가정 및 대체 비즈니스 시나리오를 평가하는 것도 이러한 이유 때문입니다.
개념 OLAP 기술 1993년 Edgar Codd에 의해 공식화되었습니다.
이 기술은 소위 OLAP 큐브(정의에서 결론지을 수 있는 것처럼 반드시 3차원일 필요는 없음)인 다차원 데이터 세트의 구성을 기반으로 합니다. OLAP 기술을 사용하는 목적은 데이터를 분석하고 이 분석을 경영진이 인식하고 이를 기반으로 의사 결정을 내리기에 편리한 형태로 제시하는 것입니다.
다변량 분석을 위한 응용 프로그램의 기본 요구 사항:
- - 합리적인 시간(5초 이내)에 분석 결과를 사용자에게 제공합니다.
- - 데이터에 대한 다중 사용자 액세스
- - 데이터의 다차원 표현
- - 저장 위치 및 볼륨에 관계없이 모든 정보에 액세스할 수 있는 기능.
OLAP 시스템 도구는 다음을 기준으로 데이터를 정렬하고 선택하는 기능을 제공합니다. 주어진 조건. 다양한 정성적, 정량적 조건을 설정할 수 있습니다.
데이터베이스 생성 및 유지 관리를 위한 수많은 도구에서 사용되는 주요 데이터 모델인 DBMS는 관계형 모델입니다. 그 안에 있는 데이터는 키 필드로 연결된 2차원 테이블 관계의 형태로 표시됩니다. 중복, 불일치를 제거하고 데이터베이스 유지 관리를 위한 인건비를 줄이기 위해 엔터티 테이블을 정규화하는 공식 장치가 사용됩니다. 그러나 메모리 리소스는 절약되지만 사용은 데이터베이스에 대한 쿼리에 대한 응답을 생성하는 데 소요되는 추가 시간과 관련이 있습니다.
다차원 데이터 모델은 연구 중인 개체를 다차원 큐브 형태로 나타내며, 3차원 모델이 더 자주 사용됩니다. 큐브의 축 또는 면을 따라 측정값 또는 속성 속성이 그려집니다. 기본 세부 사항은 큐브 셀을 채우는 것입니다. 다차원 큐브는 의사결정 지원 시스템에서 분석 작업 자료를 기반으로 보고 및 분석 문서 및 멀티미디어 프레젠테이션을 생성할 때 인식 및 프레젠테이션을 용이하게 하기 위해 3차원 큐브의 조합으로 나타낼 수 있습니다.
OLAP 기술의 프레임워크 내에서 데이터의 다차원 표현이 관계형 DBMS와 다차원 특수 도구를 통해 구성될 수 있다는 사실을 기반으로 하는 세 가지 유형의 다차원 OLAP 시스템이 있습니다.
- - 다차원(Multidimensional) OLAP-MOLAP;
- - 관계형(Relational) OLAP-ROLAP;
- - 혼합 또는 하이브리드(하이브리드) OLAP-HOLAP.
다차원 DBMS에서 데이터는 관계형 테이블의 형태가 아니라 하이퍼큐브 형태의 정렬된 다차원 배열의 형태로 구성되며, 이때 저장된 모든 데이터의 차원이 동일해야 하므로 가장 완전한 기반을 형성해야 합니다. 측정. 데이터는 폴리 큐브 형태로 구성될 수 있으며, 이 옵션에서 각 지표의 값은 자체 측정 세트와 함께 저장되며 데이터 처리는 시스템 자체 도구로 수행됩니다. 이 경우 저장 구조가 단순화됩니다. 다차원 또는 객체 지향 형태의 데이터 저장 영역이 필요하지 않습니다. 관계형 모델에서 객체 모델로 데이터를 변환하기 위한 모델 및 시스템을 만드는 데 드는 막대한 인건비가 감소합니다.
MOLAP의 장점은 다음과 같습니다.
- - ROLAP보다 요청에 대한 더 빠른 응답 - 소요 시간이 100배 또는 200배 적습니다.
- - SQL의 한계로 인해 많은 내장 기능의 구현이 어렵다.
MOLAP 제한 사항은 다음과 같습니다.
- - 데이터베이스의 상대적으로 작은 크기;
- - 비정규화 및 예비 집계로 인해 다차원 배열은 원래 데이터보다 2.5-100배 더 많은 메모리를 사용합니다(메모리 소비는 차원 수가 증가함에 따라 기하급수적으로 증가함).
- - 인터페이스 및 데이터 조작 도구에 대한 표준이 없습니다.
- - 데이터를 불러올 때 제한이 있습니다.
다차원 데이터를 생성하는 데 필요한 노력은 다음과 같이 급격히 증가합니다. 이 상황에서 정보 웨어하우스에 포함된 데이터의 관계형 모델을 객관화하는 전문화된 수단이 사실상 없습니다. 쿼리에 대한 응답 시간은 종종 OLAP 시스템의 요구 사항을 충족하지 못합니다.
ROLAP 시스템의 장점은 다음과 같습니다.
- - 스토리지에 직접 포함된 데이터를 신속하게 분석할 수 있는 기능 다수 소스 기지데이터 - 관계형;
- - 문제의 다양한 차원에서 RO-LAP이 승리합니다. 데이터베이스의 물리적 재구성이 필요하지 않습니다.
- - ROLAP 시스템은 덜 강력한 클라이언트 스테이션과 서버를 사용할 수 있으며 서버는 복잡한 SQL 쿼리를 처리하는 주요 부담을 집니다.
- - 관계형 DBMS는 정보보호 수준과 접근권한 차별화 수준이 다차원적 DBMS에 비해 비교할 수 없을 정도로 높다.
ROLAP 시스템의 단점은 성능 저하, 데이터베이스 스키마에 대한 세심한 연구, 인덱스의 특수 조정, 쿼리 통계 분석 및 데이터베이스 스키마를 수정할 때 분석 결과를 고려해야 한다는 점으로 상당한 추가 인건비가 발생합니다.
이러한 조건을 충족하면 ROLAP 시스템을 사용할 때 액세스 시간 측면에서 MOLAP 시스템과 유사한 지표를 달성하고 메모리 절약을 능가할 수 있습니다.
하이브리드 OLAP 시스템은 관계형 및 다차원 데이터 모델을 구현하는 도구의 조합입니다. 이를 통해 이러한 모델의 생성 및 유지 관리를 위한 리소스 비용, 요청에 대한 응답 시간을 대폭 줄일 수 있습니다.
이 접근 방식은 처음 두 접근 방식의 장점을 사용하고 단점을 보완합니다. 가장 발달된 곳에서 소프트웨어 제품이러한 목적을 위해 이 원칙이 실현됩니다.
OLAP 시스템에서 하이브리드 아키텍처를 사용하는 것은 다차원 분석에서 소프트웨어 도구 사용과 관련된 문제를 해결하는 가장 적합한 방법입니다.
패턴 감지 모드는 지능형 데이터 처리를 기반으로 합니다. 여기서 주요 임무는 연구 중인 프로세스의 패턴, 다양한 요인의 관계 및 상호 영향, 큰 "비정상적" 편차에 대한 검색 및 다양한 중요한 프로세스 과정의 예측을 식별하는 것입니다. 이 영역은 데이터 마이닝에 속합니다.
OLAP(OnLine Analytical Processing)는 특정 제품의 이름이 아니라 데이터 분석 및 보고를 포함하는 전체 온라인 분석 처리 기술의 이름입니다. 사용자는 다양한 섹션의 데이터를 자동으로 요약하고 계산 및 보고서 형식을 빠르게 관리할 수 있는 다차원 테이블을 제공합니다.
일부 간행물에서는 분석 처리를 온라인 및 대화식이라고 부르지만 형용사 "온라인"은 OLAP 기술의 의미를 가장 정확하게 반영합니다. 경영 관리 결정의 개발은 자동화가 가장 잘 맞는 영역의 범주에 속합니다. 그러나 오늘날에는 의사 결정 개발 과정에서 관리자를 지원할 수 있는 기회가 있으며 가장 중요한 것은 결정 개발 프로세스, 선택 및 채택 속도를 크게 높일 수 있습니다.
의사 결정 지원 시스템에는 일반적으로 초기 세트의 다양한 샘플에 대한 집계 데이터를 지각 및 분석에 편리한 형태로 사용자에게 제공하는 수단이 있습니다. 일반적으로 이러한 집계 함수는 하이퍼큐브 또는 메타큐브라고도 하는 다차원 데이터 세트를 형성하며, 축에는 매개변수가 포함되고 셀에는 이에 종속되는 집계 데이터가 포함됩니다. 이러한 데이터는 관계형 테이블에도 저장할 수 있습니다. 스토리지의 물리적 구현이 아니라 논리적 조직 데이터에 대해 이야기하는 경우입니다.
각 축을 따라 데이터를 다양한 세부 수준을 나타내는 계층 구조로 구성할 수 있습니다.
다차원 모델의 차원에 따라 기업 활동에 영향을 미치는 요소(예: 시간, 제품, 회사 지점 등)는 제외됩니다. 결과 OLAP 큐브는 기업 활동의 지표(가격, 판매, 계획, 이익, 현금 흐름 등)로 채워집니다. 기하학적 정육면체와 달리 OLAP 정육면체의 면은 같은 크기일 필요가 없습니다. 이 채우기는 운영 체제의 실제 데이터로 수행할 수 있으며 과거 데이터를 기반으로 예측할 수 있습니다. Hypercube 차원은 복잡하고 계층적일 수 있으며 차원 간에 관계를 설정할 수 있습니다. 분석하는 동안 사용자는 데이터에 대한 관점을 변경할 수 있습니다(소위 논리적 관점을 변경하는 작업). 따라서 다른 섹션에서 데이터를 보고 특정 문제를 해결할 수 있습니다. 예측 및 조건부 스케줄링(가정 분석)을 포함하여 큐브에서 다양한 작업을 수행할 수 있습니다.
이 데이터 모델 덕분에 사용자는 복잡한 쿼리를 공식화하고 보고서를 생성하며 데이터의 하위 집합을 받을 수 있습니다. 운영 분석 처리는 관리 직원이 준비하고 결정을 내리는 프로세스를 크게 단순화하고 가속화할 수 있습니다. 온라인 분석 처리는 데이터를 정보로 전환하는 목적을 제공합니다. 이는 대부분 구조화된 보고서를 고려하는 기존의 의사 결정 지원 프로세스와 근본적으로 다릅니다.
OLAP 기술은 지적 분석 유형을 나타내며 12가지 원칙을 포함합니다.
1. 개념적 다차원 표현. 사용자 분석가는 각각 기업의 세계를 본질적으로 다차원으로 보고 OLAP 모델은 그 핵심이 다차원이어야 합니다.
2. 투명도. OLAP 시스템의 아키텍처는 열려 있어야 하며 사용자가 어디에 있든 분석 도구(클라이언트)를 사용하여 서버와 통신할 수 있어야 합니다.
3. 유효성. OLAP 분석가 사용자는 관계형 데이터베이스의 전사적 데이터와 레거시 레거시 데이터베이스의 데이터, 공통 액세스 방법 및 공통 분석 모델을 포함하는 공통 개념 스키마를 기반으로 분석을 수행할 수 있어야 합니다. OLAP 시스템은 실제로 필요한 데이터에만 액세스해야 하며 불필요한 입력을 수반하는 일반적인 "주방 깔때기" 원칙을 적용하지 않아야 합니다.
4. 보고서 개발의 일관된 성능. 차원 수 또는 데이터베이스 크기가 증가해도 분석가 사용자는 성능이 크게 저하되지 않아야 합니다.
5. 클라이언트-서버 아키텍처. 오늘날 온라인 분석 처리를 받아야 하는 대부분의 데이터는 LAN을 통해 사용자 워크스테이션에 액세스할 수 있는 메인프레임에 포함되어 있습니다. 이는 OLAP 제품이 클라이언트-서버 환경에서 작동할 수 있어야 함을 의미합니다.
6. 일반 다차원성. 각 차원은 구조 및 운영 능력에 관계없이 적용되어야 합니다. 기본 데이터 구조, 수식 및 보고 형식이 어느 한 차원으로 편향되어서는 안 됩니다.
7. 희소 행렬의 동적 관리. OLAP 도구의 물리적 설계는 희소 행렬을 최적으로 관리하기 위해 특정 분석 모델에 완전히 적응할 수 있어야 합니다. 희소성(가능한 모든 셀에 대한 빈 셀의 백분율로 측정)은 데이터 전파의 특성 중 하나입니다.
8. 다중 사용자 지원. OLAP 도구는 무결성과 보안을 유지하면서 쿼리를 공유하고 여러 분석가 사용자를 보강하는 기능을 제공해야 합니다.
9. 무제한 교차 작업. 다양한 작업은 계층적 특성으로 인해 OLAP 모델에서 종속 관계를 나타낼 수 있습니다. 즉, 교차 기능입니다. 실행을 위해 분석가 사용자가 이러한 계산 및 작업을 재정의할 필요가 없어야 합니다.
10. 직관적인 데이터 조작. 분석 모델에 정의된 차원에 대한 분석가 사용자의 보기에는 OLAP 모델에서 작업을 수행하는 데 필요한 모든 정보가 포함되어야 합니다. 메뉴 시스템이나 기타 여러 사용자 인터페이스 작업을 사용할 필요가 없습니다.
11. 유연한 보고 옵션. 보고 도구는 가능한 모든 방향에서 데이터 모델에서 나온 합성 데이터 또는 정보여야 합니다. 즉, 보고서의 행, 열 또는 페이지는 OLAP 모델의 여러 차원을 동시에 표시해야 하며 차원에 포함된 요소(값)의 하위 집합을 임의의 순서로 표시할 수 있어야 합니다.
12. 무제한 차원 및 집계 수준 수. 분석 모델에 필요한 필요한 측정의 가능한 수에 대한 연구는 분석 사용자가 동시에 최대 19개의 측정을 사용할 수 있음을 보여주었습니다. 이는 OLAP 시스템에서 지원하는 차원 수에 대한 권장 사항으로 이어집니다. 또한 각 공통 차원은 사용자 분석가가 정의한 집계 수준의 수에 의해 제한되어서는 안 됩니다.
현재 시중에 나와 있는 특화된 OLAP 시스템으로 비즈니스 인텔리전스인 CalliGraph를 지정할 수 있습니다.
간단한 데이터 분석 작업을 해결하기 위해 예산 솔루션을 사용할 수 있습니다 - Office 응용 프로그램 Excel 및 Access 마이크로소프트, 피벗 테이블을 만들고 이를 기반으로 다양한 보고서를 작성할 수 있는 기본 OLAP 기술 도구가 포함되어 있습니다.
OLAP(영어 OnLine Analytical Processing - online analysis data processing, also: real-time analysis data processing, Interactive analysis data processing) - 더 넓은 영역의 일부인 다차원 계층적 표현에 기반한 분석 데이터 처리에 대한 접근 정보 기술- 비즈니스 인텔리전스 ().
TAdviser의 OLAP 섹션에서 OLAP 솔루션 및 프로젝트 카탈로그를 참조하십시오.
사용자의 입장에서, OLAP- 시스템은 다양한 섹션에서 정보를 유연하게 볼 수 있는 수단을 나타냅니다. 자동 영수증집계된 데이터, 컨볼루션의 분석 작업 수행, 세부 정보, 시간 경과에 따른 비교. 이 모든 것이 OLAP 시스템을 모든 유형의 비즈니스 보고에 대한 데이터 준비 분야에서 명백한 이점을 가진 솔루션으로 만듭니다. 예를 들어 판매 보고서, 다양한 형태의 예산 등 다양한 섹션과 다양한 계층 수준의 데이터 표시를 포함합니다. 에. 이러한 프레젠테이션의 장점은 예측을 포함한 다른 형태의 데이터 분석에서도 분명합니다.
OLAP 시스템에 대한 요구 사항. FASMI
OLAP 시스템의 핵심 요구 사항은 속도이며, 이를 통해 정보를 사용하는 분석가의 대화식 작업 프로세스에서 사용할 수 있습니다. 이러한 의미에서 OLAP 시스템은 첫째, 데이터 그룹화 및 집계를 사용하는 분석가를 위한 일반적인 쿼리에서 대기 시간 및 RDBMS 로드 측면에서 일반적으로 비용이 많이 드는 기존 RDBMS에 반대됩니다. 데이터가 복잡합니다. 둘째, OLAP 시스템은 일반적으로 사용되는 기존 스프레드시트 형식의 일반적인 플랫 파일 데이터 표현, 어렵고 직관적이지 않은 다차원 데이터 표현, 슬라이스를 변경하는 작업-요점 데이터에 대한 관점 - 또한 시간과 노력이 필요하며 데이터와의 대화형 작업이 복잡해집니다.
동시에 OLAP 시스템에 고유한 데이터 요구 사항은 일반적으로 일반적인 OLAP 작업에 최적화된 특수 구조의 데이터 저장을 의미하는 반면, 분석 프로세스 동안 기존 시스템에서 직접 데이터 추출은 상당한 손실로 이어질 것입니다. 그들의 성과에서.
따라서 데이터 소스 역할을 하는 기존 시스템과 OLAP 시스템, 그리고 OLAP 시스템과 외부 데이터 분석 및 보고 응용 프로그램 간에 가장 유연한 가져오기-내보내기 연결을 제공하는 것이 중요한 요구 사항입니다.
동시에 이러한 링크는 여러 데이터 소스에서 가져오기-내보내기 지원, 데이터 정리 및 변환 절차 구현, 사용된 분류자 및 디렉터리 통합에 대한 명백한 요구 사항을 충족해야 합니다. 또한 이러한 요구 사항은 기존의 다양한 데이터 업데이트 주기를 고려해야 하는 필요성에 의해 보완됩니다. 정보 시스템필요한 수준의 데이터 세부 정보를 통합합니다. 이 문제의 복잡성과 다양성으로 인해 데이터 웨어하우스의 개념이 등장했으며 좁은 의미에서는 별도의 클래스 데이터 변환 및 변환 유틸리티인 ETL(Extract Transform Load)을 할당하게 되었습니다.
활성 데이터 스토리지 모델
위에서 우리는 OLAP가 데이터의 다차원 계층적 표현을 가정하고 어떤 의미에서는 RDBMS 기반 시스템과 반대임을 나타냈습니다.
그러나 이것이 모든 OLAP 시스템이 다차원 모델을 사용하여 활성 "작업" 시스템 데이터를 저장한다는 것을 의미하지는 않습니다. 활성 데이터 저장 모델은 FASMI 테스트에 의해 지시된 모든 요구 사항에 영향을 미치기 때문에 OLAP 하위 유형이 전통적으로 다차원(MOLAP), 관계형(ROLAP) 및 하이브리드(HOLAP)와 같이 구별된다는 사실에 의해 중요성이 강조됩니다.
그러나 앞서 언급한 전문가들이 이끄는 일부 전문가들은 나이젤 펜즈, 하나의 기준에 기반한 분류가 충분하지 않음을 나타냅니다. 또한 기존 OLAP 시스템의 대다수는 하이브리드 유형이 될 것입니다. 따라서 활성 데이터 스토리지 모델에 대해 더 자세히 설명하고 기존 OLAP 하위 유형에 해당하는 모델을 언급합니다.
다차원 데이터베이스에 활성 데이터 저장
이 경우 OLAP 데이터는 이러한 유형의 데이터에 최적화된 구문을 사용하는 다차원 DBMS에 저장됩니다. 일반적으로 다차원 DBMS는 필요한 계층 수준별 집계 등을 포함하여 모든 일반적인 OLAP 작업도 지원합니다.
어떤 의미에서 이러한 유형의 데이터 스토리지는 OLAP의 클래식이라고 할 수 있습니다. 그러나 그에게는 사전 데이터 준비를 위한 모든 단계가 완전히 필요합니다. 일반적으로 다차원 DBMS 데이터는 디스크에 저장되지만 경우에 따라 데이터 처리 속도를 높이기 위해 RAM에 데이터를 저장할 수 있습니다. 같은 목적으로 사전 계산된 집계 값 및 기타 계산된 값의 데이터베이스 저장이 때때로 사용됩니다.
동시 읽기 및 쓰기 트랜잭션으로 다중 사용자 액세스를 완벽하게 지원하는 다차원 DBMS는 매우 드물며, 일반 모드이러한 DBMS의 경우 다중 사용자 읽기 전용 또는 다중 사용자 읽기 전용인 동안 쓰기 액세스 권한이 있는 단일 사용자입니다.
이를 기반으로 한 다차원 DBMS 및 OLAP 시스템의 일부 구현의 조건부 단점 중 하나는 사용자의 관점에서 예측할 수 없는 데이터베이스가 차지하는 공간의 증가에 대한 민감성을 확인할 수 있습니다. 이 효과는 사전 계산된 집계 지표 및 기타 수량 값을 데이터베이스에 저장하도록 지시하여 시스템 응답 시간을 최소화하려는 욕구로 인해 발생합니다. 새로운 데이터 값 또는 측정값을 추가합니다.
희소 데이터 큐브의 효율적인 저장과 관련된 문제뿐만 아니라 이 문제의 발현 정도는 OLAP 시스템의 특정 구현을 위해 적용된 접근 방식 및 알고리즘의 품질에 의해 결정됩니다.
관계형 데이터베이스에 활성 데이터 저장
OLAP 데이터는 기존 RDBMS에도 저장할 수 있습니다. 대부분의 경우 이 접근 방식은 OLAP를 기존 회계 시스템 또는 RDBMS 기반 데이터 웨어하우스와 원활하게 통합하려고 할 때 사용됩니다. 동시에 이 접근 방식은 FASMI 테스트의 요구 사항을 효과적으로 충족하기 위해 RDBMS의 몇 가지 추가 기능이 필요합니다(특히 최소 시스템 응답 시간 보장). 일반적으로 OLAP 데이터는 비정규화된 형태로 저장되며 미리 계산된 집계 및 값 중 일부는 특수 테이블에 저장됩니다. 정규화 된 형태로 저장하면 활성 데이터를 저장하는 방법으로서 RDBMS의 효율성이 떨어집니다.
사전 계산된 데이터를 저장하기 위한 효율적인 접근 방식과 알고리즘을 선택하는 문제는 RDBMS 기반 OLAP 시스템과도 관련이 있으므로 이러한 시스템 제조업체는 일반적으로 사용된 접근 방식의 장점에 중점을 둡니다.
일반적으로 RDBMS 기반 OLAP 시스템은 OLAP 작업에 대한 데이터 저장 구조가 덜 효율적이기 때문에 다차원 DBMS 기반 시스템보다 느리다고 생각되지만 실제로는 특정 시스템의 특성에 따라 다릅니다.
RDBMS에 데이터를 저장하는 것의 장점 중 하나는 일반적으로 이러한 시스템의 더 큰 확장성이라고 합니다.
"플랫" 파일에 활성 데이터 저장
이 접근 방식에는 데이터 청크를 일반 파일에 저장하는 것이 포함됩니다. 이것은 일반적으로 디스크나 디스크에 최신 데이터를 캐싱하여 작업 속도를 높이는 두 가지 주요 접근 방식 중 하나의 부속물로 사용됩니다. 랜덤 액세스 메모리클라이언트 PC.
하이브리드 스토리지 접근 방식
OLAP 시스템 자체 외에 DBMS, ETL(Extract Transform Load) 및 보고 도구를 포함하는 통합 솔루션을 홍보하는 대부분의 OLAP 시스템 제조업체는 현재 시스템 활성 데이터의 저장을 구성하기 위해 하이브리드 접근 방식을 사용하고 있습니다. RDBMS와 특수 스토리지 사이, 그리고 디스크 구조와 메모리 내 캐싱 사이에 이런저런 방식으로 배포합니다.
이러한 솔루션의 효율성은 제조업체가 어떤 데이터와 저장 위치, 그런 다음 고려 중인 시스템의 특정 기능을 평가하지 않고 클래스와 같은 솔루션의 초기 효율성에 대해 성급하게 결론을 내립니다.
OLAP(영어 온라인 분석 처리) - 분석 데이터베이스에서 다차원 쿼리의 동적 처리를 위한 일련의 방법. 이러한 데이터 소스는 일반적으로 상당히 크며 이를 처리하는 데 사용되는 도구에서 가장 중요한 요구 사항 중 하나는 고속입니다. 관계형 데이터베이스에서 정보는 잘 정규화된 별도의 테이블에 저장됩니다. 그러나 복잡한 다중 테이블 쿼리는 상당히 느립니다. 데이터 저장 구조의 특성으로 인해 OLAP 시스템의 처리 속도 측면에서 훨씬 더 나은 성능을 얻을 수 있습니다. 모든 정보는 명확하게 구성되어 있으며 두 가지 유형의 데이터 저장소가 사용됩니다. 측정(판매 시점, 고객, 직원, 서비스 등의 범주로 구분된 디렉토리 포함) 및 데이터(요소의 상호 작용 특성화 다양한 측정예를 들어, 2010년 3월 3일 판매자 A는 매장 C에서 고객 B에게 G 화폐 단위 금액만큼 서비스를 제공했습니다. 측정값은 분석 큐브의 결과를 계산하는 데 사용됩니다. 측정값은 선택한 해당 차원 및 해당 멤버별로 집계된 팩트 모음입니다. 이러한 기능으로 인해 다차원 데이터가 포함된 복잡한 쿼리는 관계형 소스보다 시간이 훨씬 적게 걸립니다.
OLAP 시스템의 주요 공급업체 중 하나는 Microsoft Corporation입니다. Microsoft SQL Server BIDS(Business Intelligence Development Studio) 및 Microsoft Office PerformancePoint Server PPS(Planning Business Modeler) 응용 프로그램에서 분석 큐브를 만드는 실제 예를 사용하여 OLAP 원칙 구현을 고려하고 다차원 데이터의 시각적 표현 가능성에 대해 알아보겠습니다. 그래프, 차트 및 표의 형태로.
예를 들어, BIDS에서 보험 회사, 직원, 파트너(클라이언트) 및 판매 시점에 대한 데이터를 기반으로 OLAP 큐브를 만들어야 합니다. 회사에서 한 가지 유형의 서비스를 제공하므로 서비스 측정이 필요하지 않다고 가정합니다.
먼저 치수를 정의하겠습니다. 다음 엔터티(데이터 범주)는 회사의 활동과 연결됩니다.
- 판매 포인트
- 직원
- 파트너
다음으로 팩트(팩트 테이블)를 저장할 하나의 테이블이 필요합니다.
테이블의 정보는 수동으로 입력할 수 있지만 가장 일반적인 방법은 다양한 소스에서 가져오기 마법사를 사용하여 데이터를 로드하는 것입니다.
다음 그림은 차원 및 팩트 테이블을 수동으로 생성하고 채우는 프로세스 흐름을 보여줍니다.
그림 1. 분석 데이터베이스의 측정 및 사실 표. 생성 순서
BIDS에서 다차원 데이터 소스를 생성한 후 해당 표현을 볼 수 있습니다(데이터 소스 보기). 이 예에서는 아래 그림과 같은 회로를 얻습니다.
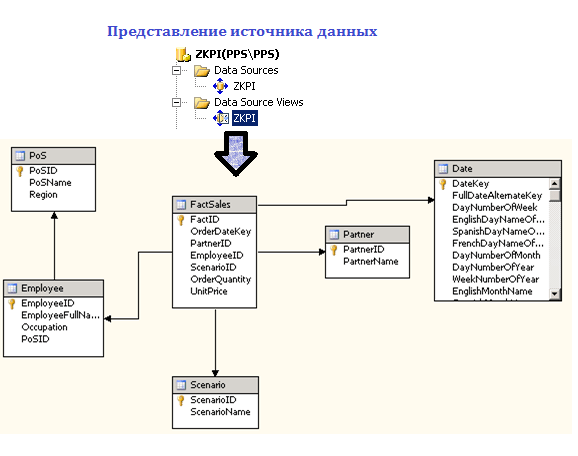
그림 2. BIDS(Business Intelligence Development Studio)의 데이터 원본 보기
보시다시피 팩트 테이블은 식별자 필드(PartnerID, EmployeeID 등)의 일대일 대응을 통해 차원 테이블과 관련됩니다.
결과를 살펴보겠습니다. 큐브 탐색기 탭에서 측정값과 차원을 합계, 행, 열 및 필터 필드로 끌어 관심 데이터를 볼 수 있습니다(예: 특정 직원이 2005년에 체결한 보험 계약).

 JavaScript - 조건부 및 부울 연산자
JavaScript - 조건부 및 부울 연산자 셀 내용 정렬
셀 내용 정렬 CSS 테이블의 열 사이의 거리
CSS 테이블의 열 사이의 거리 Windows에서 모든 환경 변수의 값을 표시하는 방법 변수의 값을 화면에 인쇄
Windows에서 모든 환경 변수의 값을 표시하는 방법 변수의 값을 화면에 인쇄