스마트 디스크 자체 테스트. SMART HDD 판독값 - 무엇이며 그 이유는 무엇입니까? 하드 드라이브의 상태를 확인하는 방법
조만간(물론 초기에 더 나은 방법으로) 모든 사용자는 자신의 컴퓨터에 설치된 하드 드라이브의 수명과 교체품을 찾아야 할 시점에 대해 스스로에게 질문합니다. 하드 드라이브는 설계 기능으로 인해 컴퓨터 구성 요소 중에서 가장 신뢰성이 낮기 때문에 놀라운 것은 아닙니다. 동시에 대부분의 사용자가 문서, 사진, 다양한 소프트웨어 등 가장 다양한 정보의 가장 큰 부분을 차지하는 것은 HDD에 있으며, 그 결과 예기치 않은 디스크 오류는 항상 비극입니다. 물론 겉보기에 "죽은" 하드 드라이브에 대한 정보는 종종 복구할 수 있지만 이 작업으로 인해 "상당 한 페니" 비용이 발생할 수 있으며 많은 신경을 쓸 것입니다. 따라서 데이터 손실을 방지하는 것이 훨씬 더 효과적입니다.
어떻게? 그것은 매우 간단합니다 ... 첫째, 정기적 인 데이터 백업을 잊지 말고 둘째, 전문 유틸리티를 사용하여 디스크 상태를 모니터링하십시오. 이 기사에서 해결되는 작업의 관점에서 이러한 종류의 여러 프로그램을 고려할 것입니다.
SMART 매개변수 및 온도 모니터링
모든 최신 HDD 및 SSD(Solid State Drive)도 S.M.A.R.T를 지원합니다. ( 영어로부터자체 모니터링, 분석 및 보고 기술은 주요 하드 드라이브 제조업체에서 제품의 신뢰성을 높이기 위해 개발한 자체 모니터링, 분석 및 보고 기술입니다. 이 기술은 자체 진단 장비(특수 센서)가 내장된 하드 디스크 상태의 지속적인 모니터링 및 평가를 기반으로 하며, 주요 목적은 드라이브의 가능한 오류를 적시에 감지하는 것입니다.
실시간으로 HDD 상태 모니터링
하드웨어 진단 및 테스트를 위한 다양한 정보 및 진단 솔루션과 특수 모니터링 유틸리티는 S.M.A.R.T. 기술을 사용합니다. 하드 드라이브의 안정성과 성능을 설명하는 다양한 필수 매개변수의 현재 상태를 모니터링합니다. 그들은 모든 최신 하드 드라이브에 장착된 센서 및 온도 센서에서 해당 매개변수를 직접 읽고 수신된 데이터를 분석하고 속성 목록과 함께 간결한 표 형식 보고서의 형태로 표시합니다. 동시에 일부 유틸리티(Hard Drive Inspector, HDDlife, Crystal Disk Info 등)는 속성 테이블 표시에 국한되지 않고(준비되지 않은 사용자에게는 값이 명확하지 않음) 간단한 정보를 추가로 표시합니다. 보다 이해하기 쉬운 형태로 디스크 상태에 대해 설명합니다.
이러한 종류의 유틸리티를 사용하여 하드 드라이브의 상태를 진단하는 것은 배를 뜯는 것만큼 쉽습니다. 설치된 HDD에 대한 간략한 기본 정보에 익숙해지기만 하면 됩니다. Crystal Disk Info의 "기술적 상태" 표시기( 그림 1) 등 어느 곳에서나 유사한 프로그램컴퓨터에 설치된 각 HDD에 대한 최소한의 필수 정보(하드 드라이브 모델 데이터, 볼륨, 작동 온도, 작업 시간, 신뢰성 및 성능 수준)가 제공됩니다. 이 정보를 통해 미디어의 성능에 대한 특정 결론을 도출할 수 있습니다.
쌀. 1. 작동 중인 HDD의 "상태"에 대한 간략한 정보
운영 체제 시작과 동시에 모니터링 유틸리티 시작을 구성하고 S.M.A.R.T. 속성 확인 사이의 시간 간격을 조정하고 시스템 트레이에 하드 드라이브의 온도 및 "상태 수준" 표시를 활성화해야 합니다. 그 후, 디스크 상태를 제어하기 위해 사용자는 때때로 시스템 트레이의 표시기를 한 눈에 보기만 하면 됩니다. 여기서 시스템의 드라이브 상태에 대한 간략한 정보가 표시됩니다: "상태" 레벨 및 온도(그림 2). 그건 그렇고, 하드 드라이브가 평범한 과열로 인해 갑자기 고장날 수 있기 때문에 작동 온도는 HDD 상태의 조건부 지표보다 덜 중요한 지표입니다. 따라서 하드 드라이브가 50 ° C 이상으로 가열되면 추가 냉각을 제공하는 것이 더 합리적입니다.
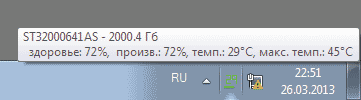
쌀. 2. 하드 디스크 상태 표시
HDDlife가 있는 시스템 트레이에
많은 유틸리티가 Windows 탐색기와의 통합을 제공하므로 제대로 작동하는 경우 로컬 디스크의 아이콘에 녹색 아이콘이 표시되고 문제가 발생하면 아이콘이 빨간색으로 변합니다. 따라서 하드 드라이브의 상태를 거의 잊을 수 없습니다. 이러한 지속적인 모니터링을 통해 유틸리티에서 S.M.A.R.T. 및 / 또는 온도에 대해 신중하게 사용자에게 알립니다(화면의 메시지, 소리 메시지 등 - 그림 3). 덕분에 무시무시한 미디어의 데이터를 미리 복사할 수 있는 시간을 가질 수 있을 것입니다.

쌀. 3. 디스크를 즉시 교체해야 한다는 메시지의 예
실제로 S.M.A.R.T. 모니터링 솔루션을 사용하여 하드 드라이브의 상태를 모니터링하는 것은 완전히 쉽습니다. 모든 유틸리티가 백그라운드에서 작동하고 최소한의 하드웨어 리소스가 필요하므로 해당 기능이 기본 워크플로를 방해하지 않기 때문입니다.
S.M.A.R.T. 속성 제어
물론 고급 사용자는 위에 제시된 유틸리티 중 하나에 대한 짧은 평결을 보고 하드 드라이브 상태를 평가하는 데 자신을 제한하지 않을 것입니다. S.M.A.R.T의 속성을 디코딩함으로써 이해할 수 있습니다. 장애의 원인을 파악할 수 있으며, 필요한 경우 신중하게 추가 조치를 취할 수 있습니다. 사실, S.M.A.R.T. 속성을 독립적으로 제어하려면 S.M.A.R.T. 기술에 대해 최소한 간략히 숙지해야 합니다.
지원되는 하드 드라이브에는 현재 상태를 "보고"할 수 있는 지능형 자가 진단 기능이 포함되어 있습니다. 이 진단 정보는 속성 모음, 즉 성능 및 안정성을 분석하는 데 사용되는 하드 드라이브의 특정 특성으로 제공됩니다.
비 영형대부분의 중요한 속성은 모든 제조업체의 드라이브에 대해 동일한 의미를 갖습니다. 정상적인 디스크 작동 중 이러한 속성의 값은 일정 간격 내에서 다를 수 있습니다. 모든 매개변수에 대해 제조업체는 정상 작동 조건에서 초과할 수 없는 특정 최소 안전 값을 정의했습니다. S.M.A.R.T.의 중요 및 진단에 중요한 매개변수를 명확하게 식별합니다. 문제. 각 속성은 고유한 정보 가치를 가지며 운송업체의 작업에서 하나 또는 다른 측면을 증언합니다. 그러나 우선 다음 속성에 주의해야 합니다.
- 원시 읽기 오류율 - 장비로 인해 디스크에서 데이터를 읽을 때 오류가 발생하는 빈도입니다.
- Spin Up Time - 디스크 스핀들을 회전시키는 평균 시간.
- 재할당된 섹터 수 - 섹터 재할당 작업의 수입니다.
- Seek Error Rate - 위치 오류의 빈도;
- 회전 재시도 횟수 - 첫 번째 시도가 실패한 경우 디스크를 작동 속도로 회전시키려는 재시도 횟수입니다.
- 현재 보류 중인 섹터 수 - 불안정한 섹터(즉, 재할당 절차를 기다리는 섹터)의 수입니다.
- Offline Scan Uncorrectable Count - 섹터 읽기/쓰기 작업 중 수정되지 않은 총 오류 수입니다.
일반적으로 S.M.A.R.T. 속성의 이름(속성), 해당 식별자(ID) 및 현재(값), 최소 임계값(임계값) 및 드라이브의 전체 작동 시간 동안 속성의 가장 낮은 값의 세 가지 값과 함께 표 형식으로 표시됩니다( Worst), 속성의 절대값(Raw). 각 속성에는 1과 100, 200 또는 253 사이의 숫자가 될 수 있는 현재 값이 있습니다(속성 값의 상한에 대한 일반적인 표준은 없음). 새로운 하드 드라이브에 대한 Value 및 Worst 값은 동일합니다(그림 4).

쌀. 4. 속성 S.M.A.R.T. 새 HDD
그림에 나와 있습니다. 4 정보를 통해 이론적으로 작동하는 하드 드라이브에는 현재(값)와 최악(최악) 값이 가능한 한 서로 가까워야 하고 대부분의 매개변수에 대한 원시 값(매개변수 제외)이 있다는 결론을 내릴 수 있습니다. : 전원 켜기 시간, HDA 온도 및 기타)는 0에 접근해야 합니다. 현재 값은 시간이 지남에 따라 변경될 수 있으며, 이는 대부분의 경우 속성에서 설명하는 하드 디스크 매개변수의 성능 저하를 반영합니다. 이것은 그림에서 볼 수 있습니다. 5, S.M.A.R.T. 동일한 디스크에 대해 - 데이터는 6개월 간격으로 수신되었습니다. 보시다시피 최신 버전의 S.M.A.R.T. 디스크에서 데이터를 읽을 때 발생하는 오류의 빈도(Raw Read Error Rate)의 증가, 그 원인은 디스크의 하드웨어에 기인하며, 자기 헤드 유닛의 위치 결정 시 오류의 빈도(Seek Error Rate) , 이는 하드 드라이브의 과열과 바구니의 불안정한 위치를 나타낼 수 있습니다 ... 속성의 현재 값이 임계값에 접근하거나 임계값 미만이 되면 하드 디스크를 신뢰할 수 없는 것으로 간주하므로 긴급하게 변경해야 합니다. 예를 들어, 스핀업 시간 속성 값(디스크 스핀들의 평균 스핀업 시간)이 임계값 아래로 떨어지면 일반적으로 역학이 완전히 마모되었음을 나타내며, 그 결과 디스크가 더 이상 제조업체가 지정한 회전 속도를 유지할 수 없습니다. 따라서 HDD의 상태를 모니터링하고 주기적으로(예: 2~3개월에 한 번) S.M.A.R.T를 진단해야 합니다. 수신한 정보를 저장하고 텍스트 파일... 앞으로 이러한 데이터를 현재 데이터와 비교할 수 있으며 상황의 발전에 대해 특정 결론을 도출할 수 있습니다.

쌀. 5. 반년 간격으로 얻은 속성 테이블 S.M.A.R.T.
(아래 S.M.A.R.T.의 최신 버전)
S.M.A.R.T. 속성을 볼 때 우선 기본 색상(일반적으로 파란색 또는 녹색) 이외의 표시기로 강조 표시된 매개변수뿐만 아니라 중요한 매개변수에 주의를 기울여야 합니다. S.M.A.R.T. 속성의 현재 상태에 따라 다릅니다. 일반적으로 테이블에 한 가지 또는 다른 색상으로 표시되어 상황을 더 쉽게 이해할 수 있습니다. 특히 Hard Drive Inspector 프로그램에서 색상 표시기는 녹색, 황록색, 노란색, 주황색 또는 빨간색이 될 수 있습니다. 녹색 및 황록색은 모든 것이 정상임을 나타냅니다(속성 값이 변경되거나 미미하게 변경되지 않음 ) 및 노란색, 주황색 및 빨간색 색상은 위험을 나타냅니다(가장 나쁜 빨간색은 속성 값이 임계값에 도달했음을 나타냄). 중요한 매개변수가 빨간색 아이콘으로 표시된 경우 하드 드라이브를 긴급히 교체해야 합니다.
이전에 모니터링 유틸리티에서 제공한 간략한 평가인 Hard Drive Inspector 프로그램에서 동일한 디스크의 S.M.A.R.T. 속성 표를 살펴보겠습니다. 무화과에서. 6 모든 속성의 값이 정상이고 모든 매개변수가 녹색으로 표시되어 있음을 알 수 있습니다. HDDlife 및 Crystal Disk Info 유틸리티도 비슷한 그림을 보여줍니다. 사실, HDD 분석 및 진단을 위한 보다 전문적인 솔루션은 그다지 충실하지 않으며 종종 S.M.A.R.T. 속성에 더 세심하게 레이블을 지정합니다. 예를 들어, 우리의 경우 HD Tune Pro 및 HDD Scan과 같은 잘 알려진 유틸리티는 외부 인터페이스를 통해 정보를 전송할 때 발생하는 오류 수를 표시하는 UltraDMA CRC 오류 속성을 의심했습니다(그림 7). 이러한 오류는 일반적으로 교체가 필요할 수 있는 꼬이고 품질이 좋지 않은 SATA 케이블로 인해 발생합니다.

쌀. 6. 표 S.M.A.R.T.-하드 드라이브 검사기 프로그램에서 얻은 속성

쌀. 7. S.M.A.R.T.-속성 상태 평가 결과
HD Tune Pro 및 HDD 스캔 유틸리티
비교를 위해 아주 오래되었지만 여전히 작동하는 HDD의 S.M.A.R.T. 속성을 살펴보겠습니다. 간헐적인 문제가 있습니다. 이것은 Crystal Disk Info 프로그램에 대한 확신을 불러일으키지 않았습니다. 기술 상태 표시기에서 디스크 상태는 경고로 평가되었고 재할당된 섹터 수 속성은 노란색으로 강조 표시되었습니다(그림 8). 이것은 디스크가 읽기/쓰기 오류를 감지할 때 재할당된 섹터 수를 나타내는 디스크의 "상태" 관점에서 매우 중요한 속성입니다. 이 작업 중에 불량 섹터의 데이터가 예비 디스크로 전송됩니다 지역. 매개변수 옆에 있는 표시기의 노란색은 불량 섹터를 교체하는 데 사용할 수 있는 예비 섹터가 거의 없으며 곧 새로 출현하는 불량 섹터를 재할당할 것이 없음을 나타냅니다. 전문가가 널리 사용하는 HDDScan 유틸리티와 같은 보다 심각한 솔루션이 디스크 상태를 평가하는 방법도 확인해 보겠습니다. 하지만 여기서는 정확히 동일한 결과를 볼 수 있습니다(그림 9).
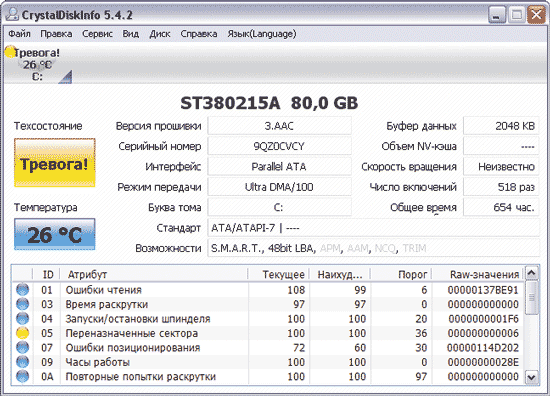
쌀. 8. CrystalDiskInfo에서 문제가 있는 하드 드라이브 평가

쌀. 9. HDDScan에서 HDD의 S.M.A.R.T. 진단 결과
즉, 운영 체제가 힘든 주어진물론 디스크는 설치할 수 없습니다. 많은 수의 재할당된 섹터가 있는 경우 읽기/쓰기 속도가 떨어지고(자기 헤드가 수행해야 하는 불필요한 움직임으로 인해) 디스크가 눈에 띄게 느려지기 시작합니다.
불량 섹터에 대한 표면 스캔
불행히도 실제로는 SMART 매개변수와 온도만 제어해야 합니다. 디스크에 문제가 있다는 약간의 증거가 나타나면(예: 결과를 저장할 때, 읽기 오류 메시지를 표시할 때 프로그램이 주기적으로 정지되는 경우) 읽을 수 없는 섹터가 있는지 디스크 표면을 스캔해야 합니다. 이러한 미디어 검사를 수행하기 위해 예를 들어 HD Tune Pro 및 HDDScan 유틸리티 또는 하드 드라이브 제조업체의 진단 유틸리티를 사용할 수 있지만 이러한 유틸리티는 자체 하드 드라이브 모델에서만 작동하므로 고려하지 않습니다.
이러한 솔루션을 사용할 때 스캔한 디스크의 데이터가 손상될 위험이 있습니다. 한편으로는 디스크에 있는 정보를 사용하여 드라이브에 실제로 결함이 있는 것으로 판명되면 스캔하는 동안 모든 일이 발생할 수 있습니다. 반면, 쓰기 모드에서 실수로 스캔을 시작하는 사용자 측의 잘못된 동작을 배제하는 것은 불가능하며, 이 동안 하드 드라이브의 데이터는 섹터별로 특정 서명으로 지워집니다. , 그리고 이 과정의 속도를 바탕으로 하드디스크의 상태에 대한 결론을 내린다. 따라서 특정 예방 규칙을 준수하는 것이 절대적으로 필요합니다. 유틸리티를 시작하기 전에 정보의 백업 복사본을 만들고 확인하는 동안 해당 소프트웨어 개발자의 지침에 따라 엄격하게 행동해야 합니다. 보다 정확한 결과를 얻으려면 스캔하기 전에 모든 활성 응용 프로그램을 닫고 백그라운드 프로세스를 언로드하는 것이 좋습니다. 또한 시스템 HDD를 테스트해야 하는 경우 플래시 드라이브에서 부팅하고 스캔 프로세스를 시작하거나 하드 드라이브를 완전히 제거하고 다른 컴퓨터에 연결해야 한다는 점을 염두에 두어야 합니다. 디스크 테스트를 시작할 수 있습니다.
예를 들어, HD Tune Pro를 사용하여 위의 Crystal Disk Info 유틸리티에 대한 확신을 불러일으키지 못한 불량 섹터가 있는지 HDD 표면을 확인하겠습니다. 이 프로그램에서 스캔 프로세스를 시작하려면 원하는 디스크, 탭을 활성화 오류 스캔그리고 버튼을 클릭 시작... 그 후 유틸리티는 디스크의 순차적 스캔을 시작하여 섹터별로 섹터를 읽고 디스크 맵의 섹터를 여러 색상의 사각형으로 표시합니다. 상황에 따라 사각형의 색상은 녹색(일반 섹터) 또는 빨간색(불량 블록)일 수 있으며 이러한 색상 사이에 중간 음영이 있습니다. 그림에서 볼 수 있듯이 10, 우리의 경우 유틸리티는 본격적인 불량 블록을 찾지 못했지만 그럼에도 불구하고 하나 또는 다른 읽기 지연이 있는 상당한 수의 섹터가 있습니다(색상으로 판단). 이 외에도 디스크 중간 부분에는 색상이 빨간색에 가까운 작은 섹터 블록이 있습니다. 이 섹터는 아직 유틸리티에서 나쁜 것으로 인식되지 않았지만 이미 이것에 가깝고 아주 가까운 장래에 나쁜 것으로 분류될 것입니다.

쌀. 10. HD Tune Pro에서 표면의 불량 섹터 스캔
HDDScan에서 불량 섹터에 대한 매체를 테스트하는 것은 더 어렵고 훨씬 더 위험합니다. 모드를 잘못 선택한 경우 디스크의 정보가 복구 불가능하게 손실되기 때문입니다. 우선 스캔을 시작하려면 버튼을 클릭하여 새 작업을 만듭니다. 새 작업목록에서 명령 선택 표면 테스트... 그런 다음 모드가 선택되어 있는지 확인해야 합니다. 읽다- 이 모드는 기본적으로 설정되어 있으며 사용할 때 하드 디스크 표면을 읽기(즉, 데이터 삭제 없이)로 테스트합니다. 그런 다음 버튼을 클릭하십시오. 테스트 추가(그림 11) 생성된 작업을 두 번 클릭합니다. RD-읽기... 이제 열리는 창에서 그래프(그래프) 또는 지도(지도)에서 디스크를 스캔하는 과정을 관찰할 수 있습니다. 12. 프로세스가 완료되면 위에서 HD Tune Pro 유틸리티에서 설명한 것과 거의 동일한 결과를 얻을 수 있지만 더 명확한 해석이 가능합니다. 불량 섹터는 없지만(파란색으로 표시됨) 세 개의 섹터가 있습니다. 500ms(빨간색으로 표시) 이상의 응답 시간으로 인해 실제 위험이 발생합니다. 6개의 주황색 섹터(150~500ms의 응답 시간)의 경우 이러한 응답 지연은 예를 들어 백그라운드 프로그램 실행과 같은 형태의 일시적인 간섭으로 인해 종종 발생하기 때문에 정상 범위 내로 간주할 수 있습니다.

쌀. 11. HDDScan에서 디스크 테스트 시작

쌀. 12. HDDScan을 사용하여 읽기 모드에서 디스크를 스캔한 결과
또한 불량 블록의 수가 적은 경우 HDDScan을 사용하여 선형 기록 모드(Erase)에서 디스크 표면을 스캔하여 불량 섹터를 제거하여 하드 디스크의 상태를 개선할 수 있다는 점에 유의해야 합니다. 이러한 작업 후에도 디스크는 한동안 계속 사용할 수 있지만 물론 시스템용으로는 사용할 수 없습니다. 그러나 HDD가 이미 무너지기 시작했기 때문에 기적에 의존해서는 안되며 가까운 장래에 결함 수가 증가하지 않고 드라이브가 완전히 실패하지 않을 것이라는 보장이 없습니다.
S.M.A.R.T. 모니터링 및 HDD 테스트용 프로그램
HD Tune Pro 5.00 및 HD Tune 2.55
개발자: EFD 소프트웨어
배포 크기: HD Tune Pro - 1.5MB; HD 튠 - 628KB
통제하에 작업:윈도우 XP / 서버 2003 / 비스타 / 7
배포 방법: HD Tune Pro - 셰어웨어(15일 데모) HD Tune - 프리웨어(http://www.hdtune.com/download.html)
가격: HD 튠 프로 - $34.95; HD Tune - 무료(비상업적 용도만 해당)
HD Tune은 HDD/SSD(표 참조)는 물론 메모리 카드, USB 디스크 및 기타 여러 저장 장치를 진단하고 테스트하기 위한 편리한 유틸리티입니다. 프로그램은 드라이브에 대한 자세한 정보를 표시합니다(펌웨어 버전, 일련 번호, 디스크 공간, 버퍼 크기 및 데이터 전송 모드) 및 S.M.A.R.T. 데이터를 사용하여 장치 상태를 설정할 수 있습니다. 및 온도 모니터링. 또한 일련의 테스트(순차 및 임의 읽기/쓰기 속도 테스트, 파일 성능 테스트, 캐시 테스트 및 여러 추가 테스트)를 수행하여 디스크 표면의 오류를 테스트하고 장치의 성능을 평가하는 데 사용할 수 있습니다. 또한 유틸리티를 사용하여 AAM을 구성하고 데이터를 안전하게 삭제할 수 있습니다. 이 프로그램은 상업용 HD Tune Pro와 무료 라이트 HD Tune의 두 가지 버전으로 제공됩니다. HD Tune 에디션에서는 디스크 및 S.M.A.R.T. 속성 테이블에 대한 자세한 정보만 볼 수 있을 뿐 아니라 디스크에서 오류를 스캔하고 읽기 모드에서 속도를 테스트할 수 있습니다(낮은 수준 벤치마크 - 읽기).
상태 탭은 프로그램의 S.M.A.R.T. 속성을 모니터링하는 역할을 합니다. 센서의 데이터는 일정 시간이 지나면 읽혀지고 결과는 테이블에 표시됩니다. 모든 속성에 대해 숫자 형식과 그래프에서 변경 내역을 볼 수 있습니다. 모니터링 데이터는 자동으로 로그에 기록되지만 매개변수의 중요한 변경에 대한 사용자 알림은 제공되지 않습니다.
불량 섹터에 대한 디스크 표면 스캔과 관련하여 탭은 이 작업을 담당합니다. 오류 주사... 스캔은 빠르고(빠른 스캔) 심층적일 수 있습니다. 빠른 스캔 중에는 전체 디스크가 스캔되지 않고 일부만 스캔됩니다(스캔 영역은 시작 및 종료 필드를 통해 결정됨). 손상된 섹터는 디스크 맵에 빨간색 블록으로 표시됩니다.
HDD스캔 3.3
개발자:아르템 루브초프
배포 크기: 3.64MB
통제하에 작업:윈도우 2000(SP4) / XP(SP2 / SP3) / 서버 2003 / 비스타 / 7
배포 방법:프리웨어(http://hddscan.com/download/HDDScan-3.3.zip)
가격:무료이다
HDDScan은 하드 드라이브, 솔리드 스테이트 드라이브 및 USB 플래시 드라이브의 낮은 수준 진단을 위한 유틸리티입니다. 이 프로그램의 주요 목적은 불량 블록 및 불량 섹터에 대해 디스크를 테스트하는 것입니다. 이 유틸리티는 SMART 콘텐츠를 보고 온도를 모니터링하며 일부 하드 디스크 설정을 변경하는 데에도 사용할 수 있습니다. 소음 관리(AAM), 전원 관리(APM), 드라이브 스핀들의 강제 시작/중지 등. 이 프로그램은 설치 없이 작동하며 다음을 수행할 수 있습니다. 플래시 드라이브와 같은 휴대용 미디어에서 실행할 수 있습니다.
S.M.A.R.T.-속성 표시 및 HDDScan의 온도 모니터링은 요청 시 수행됩니다. S.M.A.R.T. 보고서 표준 속성 테이블 형식으로 드라이브의 성능 및 "상태"에 대한 정보를 포함하고 드라이브 온도는 시스템 트레이와 특수 정보 창에 표시됩니다. 보고서를 인쇄하거나 MHT 파일로 저장할 수 있습니다. S.M.A.R.T. 테스트가 가능합니다.
디스크 표면 검사는 확인(선형 검증 모드), 읽기(선형 읽기), 지우기(선형 쓰기) 및 버터플라이 읽기(Butterfly 읽기 모드)의 네 가지 모드 중 하나로 수행됩니다. 디스크에 불량 블록이 있는지 확인하기 위해 일반적으로 읽기 모드의 테스트가 사용되며, 이를 통해 데이터를 삭제하지 않고 표면을 테스트합니다(드라이브 상태에 대한 결론은 섹터 속도를 기준으로 합니다 -섹터별 데이터 읽기). 선형 기록 모드(Erase)에서 테스트할 때 디스크의 정보를 덮어쓰지만 이 테스트는 디스크를 어느 정도 치유하여 불량 섹터로부터 저장할 수 있습니다. 모든 모드에서 전체 디스크 또는 디스크의 특정 조각을 테스트할 수 있습니다(스캔 영역은 초기 및 최종 논리 섹터(각각 시작 LBA 및 끝 LBA)를 지정하여 결정됨). 테스트 결과는 보고서(보고서 탭) 형식으로 표시되며 무엇보다도 불량 섹터(불량) 및 섹터 수, 응답 시간을 나타내는 그래프(그래프) 및 디스크 맵(맵)에 표시됩니다. 그 중 테스트 중에 500ms 이상이 소요되었습니다(빨간색으로 표시).
하드 드라이브 검사기 4.13
개발자:알트릭스소프트
배포 크기: 2.64MB
통제하에 작업:윈도우 2000 / XP / 2003 서버 / 비스타 / 7
배포 방법:셰어웨어(14일 데모 버전 - http://www.altrixsoft.com/ru/download/)
가격: 하드 드라이브 검사기 전문가 - 600 루블; 노트북용 하드 드라이브 검사기 - 800루블.
Hard Drive Inspector는 외부 및 내부 HDD의 S.M.A.R.T. 모니터링을 위한 편리한 솔루션입니다. 현재 시장에 나와 있는 이 프로그램은 기본 Hard Drive Inspector Professional과 노트북용 휴대용 Hard Drive Inspector의 두 가지 버전으로 제공됩니다. 후자는 Professional 버전의 모든 기능을 포함하는 동시에 랩톱 하드 드라이브 모니터링의 세부 사항을 고려합니다. 이론상으로는 다른 버전의 SSD가 있지만 OEM 납품으로만 유통된다.
이 프로그램은 지정된 간격으로 SMART 속성을 자동으로 검사하고 완료 시 "신뢰성", "성능" 및 "오류 없음"과 같은 특정 조건 표시기의 값을 표시하여 드라이브 상태에 대한 판정을 내립니다. 온도 및 온도 도표의 수치. 또한 디스크 모델, 용량, 총 여유 공간 및 작동 시간(일)에 대한 기술 데이터를 제공합니다. 고급 모드에서는 디스크 매개변수(버퍼 크기, 펌웨어 이름 등) 및 S.M.A.R.T.속성 테이블에 대한 정보를 볼 수 있습니다. 디스크에 중요한 변경 사항이 있는 경우 사용자에게 알리는 다양한 옵션이 있습니다. 또한 유틸리티를 사용하여 하드 드라이브에서 발생하는 소음 수준을 줄이고 HDD의 전력 소비를 줄일 수 있습니다.
HDD라이프 4.0
개발자:(주)바이너리센스
배포 크기: 8.45MB
통제하에 작업:윈도우 2000 / XP / 2003 / 비스타 / 7/8
배포 방법:셰어웨어(15일 데모 버전 - http://hddlife.ru/rus/downloads.html)
가격: HDDLife - 무료; HDDLife Pro - 300루블; 노트북용 HDDlife - 500루블.
HDDLife는 하드 드라이브 및 SSD(버전 4.0부터)의 상태를 모니터링하도록 설계된 간단한 유틸리티입니다. 이 프로그램은 무료 HDDLife와 두 가지 상업용(기본 HDDLife Pro 및 노트북용 휴대용 HDDlife)의 세 가지 버전으로 제공됩니다.
유틸리티는 지정된 간격으로 SMART 속성과 온도를 모니터링하고 분석 결과를 기반으로 디스크 모델 및 용량, 작업 시간, 온도에 대한 기술 데이터를 나타내는 디스크 상태에 대한 요약 보고서를 발행하고 상태 및 성능의 조건부 백분율로 초보자도 상황을 탐색할 수 있습니다. 고급 사용자는 S.M.A.R.T. 속성 테이블을 추가로 볼 수 있습니다. 하드 드라이브에 문제가 있는 경우 알림을 구성하는 기능이 제공됩니다. 디스크가 정상 상태일 때 검사 결과가 표시되지 않도록 프로그램을 구성할 수 있습니다. HDD 소음 수준 및 소비 전력을 제어할 수 있습니다.
크리스탈디스크인포 5.4.2
개발자:히요히요
배포 크기: 1.79MB
통제하에 작업:윈도우 XP / 2003 / 비스타 / 2008/7/8/2012
배포 방법:프리웨어(http://crystalmark.info/download/index-e.html)
가격:무료이다
CrystalDiskInfo는 S.M.A.R.T.-하드 드라이브(많은 외장 HDD 포함) 및 SSD의 상태 모니터링을 위한 간단한 유틸리티입니다. 무료임에도 불구하고 이 프로그램에는 디스크 상태 모니터링을 구성하는 데 필요한 모든 기능이 있습니다.
디스크는 지정된 시간(분) 후 또는 요청 시 자동으로 모니터링됩니다. 검사가 끝나면 모니터링되는 장치의 온도가 시스템 트레이에 표시됩니다. S.M.A.R.T. 매개변수, 온도 및 장치 상태에 대한 프로그램 판정 값이 포함된 HDD에 대한 자세한 정보는 유틸리티의 기본 창에서 확인할 수 있습니다. 일부 매개변수의 임계값을 설정하고 초과 시 사용자에게 자동으로 알리는 기능이 있습니다. 소음 수준 관리(AAM) 및 전력 관리(APM)가 가능합니다.
불행히도 최신 HDD의 대부분은 1년 조금 넘게 정상적으로 작동한 다음 모든 종류의 문제가 시작되어 시간이 지남에 따라 데이터 손실로 이어질 수 있습니다. 예를 들어 기사에서 설명한 유틸리티를 사용하여 하드 디스크의 상태를 주의 깊게 모니터링하면 이러한 가능성을 완전히 피할 수 있습니다. 그러나 모니터링 유틸리티는 일반적으로 "역학"의 오류로 인한 디스크 오류를 성공적으로 예측하기 때문에 귀중한 데이터의 정기적인 백업도 잊지 말아야 합니다(Seagate 통계에 따르면 HDD의 약 60%는 기계 부품), 하지만 드라이브의 전자 부품 문제로 인해 드라이브의 사망을 예측할 수 없습니다.
의심되는 상태, 가장 먼저 할 일은 SMART 기술 데이터를 확인하는 것입니다. 이 기술은 하드 디스크의 상태에 대한 정보를 수집하고 자가 진단 절차를 수행하도록 설계되었습니다. 와 함께 스마트와 함께데이터 손실 위험이 있는지 여부와 컴퓨터를 추가 진단 및 수리하기 위해 수행해야 하는 작업 등 하드 드라이브의 상태를 빠르게 평가할 수 있습니다.
SMART 기술(또는 S.M.A.R.T.)은 1992년에 하드 드라이브에 등장했습니다. 그런 다음 이 시스템의 첫 번째 드라이브는 IBM의 디스크 어레이였습니다. 그 이후로 SMART는 널리 사용되어 현재 절대적으로 모든 HDD 및 대부분의 SSD 드라이브에 사용됩니다.
CrystalDiskInfo 프로그램의 인터페이스는 매우 간단하며 초보자도 이해할 수 있습니다. 창 상단에는 컴퓨터에 연결된 디스크 목록이 있습니다. 하드 디스크를 선택하면 이 HDD에 사용할 수 있는 모든 정보가 창 하단에 나타납니다.
다음은 선택한 드라이브에 대한 기본 정보 블록입니다. 여기에서 디스크 이름, 펌웨어 버전, 일련 번호, 사용된 인터페이스, 스핀들 속도, 시작 횟수, 총 작동 시간 및 기타 정보를 확인할 수 있습니다.

기본 정보가 있는 블록에서 가장 중요한 데이터는 "시작 횟수"와 "총 작동 시간"입니다. 이 값이 높을수록 하드 디스크는 작동 중에 필연적으로 열화되기 때문에 하드 디스크의 상태가 나빠집니다. 데스크톱 컴퓨터에서 최신 드라이브는 일반적으로 15-25,000시간 동안 정상적으로 작동한 후 문제가 나타나기 시작합니다. 랩톱의 경우 디스크가 일반적으로 10-20,000 시간 이상을 견딜 수없는이 숫자는 훨씬 적습니다.

창 왼쪽에 더 중요한 두 가지 옵션이 있습니다. 이것은 하드 드라이브의 기술적 상태와 온도에 대한 평가입니다. 하드 디스크 상태 점수는 프로그램이 SMART 기술 데이터를 기반으로 할당하는 일반 점수입니다. 이 평가는 다음 세 가지 값 중 하나를 사용할 수 있습니다.
- 양호 - 디스크에 문제가 없으며 조치가 필요하지 않습니다.
- 불안 - 디스크에 몇 가지 문제가 있습니다. 백업 가용성을 확인하는 것이 좋습니다. 디스크를 교체하는 것이 좋습니다.
- 불량 - 디스크에 심각한 문제가 있어 디스크를 교체해야 합니다.
그의 상태와 직접적인 관련이 없습니다. HDD의 정상 온도는 섭씨 20~45도입니다. 온도가 45도를 초과하면 컴퓨터 케이스의 냉각 상태가 좋지 않음을 나타냅니다.

하드 드라이브 상태에 대한 가장 유용한 정보는 프로그램 창 하단에 있습니다. 다음은 SMART 기술이 모니터링하는 매개변수 목록과 그에 할당된 값입니다. 이 정보를 사용하여 HDD의 상태를 빠르게 평가하고 추가 조치를 결정할 수 있습니다.

SMART 매개변수 목록을 볼 때 "RAW 값" 열의 값을 보십시오. 여기에 있는 데이터는 HEX 형식입니다.

SMART 기술로 모니터링되는 매개변수 목록은 상당히 많지만 모든 매개변수가 하드 디스크의 상태에 매우 중요한 것은 아닙니다. 아래에서는 가장 중요한 것만 고려할 것입니다.
- 03 - 스핀업 시간- 디스크가 꺼진 상태에서 작동 속도로 회전하는 데 걸리는 시간입니다. 이 값은 드라이브의 기계 부품이 마모되면 증가하며 스핀업 시간이 길면 드라이브가 시작될 때 전압 강하가 나타날 수 있습니다.
- 05 - 재할당된 섹터 수- 결함이 있는 것으로 발견되어 예비 영역에 재할당된 섹터의 수. 재할당된 섹터는 디스크 표면에 문제가 있음을 나타냅니다.
- 0A - 스핀업 재시도 횟수- 디스크 회전을 반복적으로 시도한 횟수입니다. 이 값은 드라이브의 기계적 부분이 마모됨에 따라 증가합니다.
- BB - 보고된 UNC 오류- 드라이브의 하드웨어에서 제거할 수 없는 오류의 수입니다.
- BC - 명령 시간 초과- 시간 초과로 인해 중단된 작업 수입니다. 이 매개변수가 증가하면 드라이브의 전원이나 케이블에 문제가 있음을 나타낼 수 있습니다.
- C4 - 섹터 재할당 시도(재할당 이벤트 수)- 섹터 재할당 작업을 수행하려는 시도 횟수. 섹터 재할당에 대한 성공 및 실패 시도가 모두 고려됩니다. 재할당 시도는 디스크 표면에 문제가 있음을 나타냅니다.
- C5 - 불안정한 섹터(현재 보류 중인 섹터 수)- 미래에 재할당될 수 있는 의심스러운 섹터의 수. 불안정한 섹터가 있으면 디스크 표면에 문제가 있음을 나타냅니다.
- C6 - 수정할 수 없는 섹터 수- 하드 디스크로 고정할 수 없는 섹터 수. 치명적인 오류는 디스크의 표면이나 기계적 부분에 문제가 있음을 나타냅니다.
위의 모든 매개 변수에 대한 RAW 값이 0이면 하드 드라이브가 우수한 상태임을 나타냅니다. SMART 기술은 문제를 나타내지 않았습니다. 일부 매개변수의 값이 0보다 큰 경우 HDD 상태를 더 주의 깊게 확인해야 합니다. 아마도 그러한 디스크를 가능한 한 빨리 교체해야 할 것입니다.

가장 중요한 SMART 설정은 재할당된 섹터 수입니다. 디스크에 의해 예비 영역에 재할당된 불량 섹터의 수를 나타냅니다. 일반적으로 다시 매핑된 섹터가 몇 개 나타난 후 디스크 표면이 빠르게 저하되기 시작하고 며칠 또는 몇 주 후에 드라이브가 완전히 실패합니다.
따라서 재할당된 섹터가 감지되면 해당 디스크에 저장된 모든 중요 데이터의 백업을 확인해야 합니다. 백업이 없으면 긴급하게 수행해야 합니다. 그렇지 않으면 데이터가 손실될 위험이 있습니다.
오늘은 하드디스크 선택의 기준에 대해 이전 글에서 언급한 SMART 기술에 대해 조금 더 이야기해보고자 하며, 또한 특수 프로그램으로 표면을 확인할 때 불량 섹터의 출현 여부에 대한 궁금증과 재할당을 위한 예비 표면의 고갈 - 마지막 기사에서 제기된 질문.
언제나처럼 짧은 역사 여행으로 시작합니다. 하드 드라이브(그리고 가장 일반적인 경우 모든 저장 장치)의 신뢰성은 항상 가장 중요합니다. 그리고 요점은 비용이 아니라 그가 다른 세계로 가져간 정보의 가치에 있으며, 삶을 스스로 떠나고, 하드 드라이브가 고장날 때 가동 중지 시간과 관련된 이익 손실에 대해 이야기하고 있습니다. 정보가 남아 있더라도 비즈니스 사용자. 그리고 그러한 불쾌한 순간에 대해 미리 알고 싶어하는 것은 아주 자연스러운 일입니다. 가정 수준의 평범한 추론조차도 작동 중인 장치의 상태를 관찰하는 것이 그러한 순간을 암시할 수 있음을 시사합니다. 어떻게 든이 관찰을 하드 드라이브에서 구현하는 것만 남아 있습니다.
처음으로 청색 거인(IBM, 즉)의 엔지니어들은 이 문제에 대해 생각했습니다. 그리고 1995년에는 드라이브의 몇 가지 중요한 매개변수를 모니터링하고 수집된 데이터를 기반으로 드라이브의 오류를 예측하는 기술인 PFA(Predictive Failure Analysis)를 제안했습니다. 이 아이디어는 나중에 자체 기술인 IntelliSafe를 만든 Compaq에서 채택했습니다. Seagate, Quantum 및 Conner도 Compaq 개발에 기여했습니다. 그들이 만든 기술은 또한 여러 디스크 성능 특성을 모니터링하여 허용 가능한 값과 비교하고 위협이 발생할 경우 호스트 시스템에 다시 보고했습니다. 이는 하드 드라이브의 신뢰성을 높이는 것이 아니라 적어도 하드 드라이브를 사용할 때 정보 손실 위험을 줄이는 데 있어 큰 진전이었습니다. 첫 번째 시도는 성공적이었고 필요성을 보여주었습니다. 추가 개발기술. 이미 모든 주요 하드 드라이브 제조업체의 연합에서 IntelliSafe 및 PFA 기술을 기반으로 하는 SMART(자체 모니터링 분석 및 보고 기술) 기술이 등장했습니다(그런데 PFA는 오늘날에도 다양한 하위 시스템을 모니터링 및 분석하기 위한 일련의 기술로 존재합니다. 디스크 하위 시스템을 포함한 IBM 서버의 모니터링 및 후자의 모니터링은 정확히 SMART 기술을 기반으로 합니다.
따라서 SMART는 디스크의 상태를 내부적으로 평가하는 기술이자 하드디스크의 고장 가능성을 예측하는 메커니즘입니다. 원칙적으로 기술은 발생하는 문제를 해결하지 않으며(주요 문제는 아래 그림에 표시됨) 이미 발생한 문제 또는 가까운 장래에 예상되는 문제에 대해서만 경고할 수 있습니다.
동시에 기술은 가능한 모든 문제를 절대적으로 예측할 수 없으며 이것은 논리적입니다. 전압 서지로 인한 전자 장치의 출력, 충격으로 인한 헤드 및 표면 손상, 등. 어떤 기술도 예측할 수 없습니다. 일부 특성의 점진적인 저하, 일부 구성 요소의 균일한 저하와 관련된 문제만 예측할 수 있습니다.
기술 개발 단계
SMART 기술은 개발 과정에서 세 단계를 거쳤습니다. 1세대에서는 소수의 매개변수에 대한 관찰이 실현되었습니다. 드라이브의 독립적인 동작은 예상되지 않았습니다. 발사는 인터페이스를 통한 명령에 의해서만 수행되었습니다. 표준을 완전히 설명하는 사양이 없기 때문에 어떤 매개변수를 제어해야 하는지에 대한 명확한 예측도 없었습니다. 더욱이, 감소의 허용 가능한 수준에 대한 정의와 결정은 전적으로 하드 드라이브 제조업체에 맡겨졌습니다(제조업체는 모든 하드 드라이브가 너무 다르기 때문에 주어진 하드 드라이브에서 정확히 무엇을 제어해야 하는지 더 잘 알고 있기 때문에 자연스러운 현상입니다. ). 이러한 이유로 타사에서 작성한 소프트웨어는 일반적으로 보편적이지 않으며 임박한 오류를 잘못 보고할 수 있습니다(다른 제조업체가 다른 매개변수의 값을 저장했다는 사실로 인해 혼란이 발생했습니다. 동일한 식별자). 고장 전 상태를 감지하는 경우가 극히 적다는 불만이 많다(인간의 본성: 한번에 다 받고 싶다, SAMRT가 구현되기 전에 갑자기 디스크 고장이 난다고 하소연한다. 아무도 그것에 대해 생각하지 않았습니다). 대부분의 경우 최소한의 필요한 요구 사항 SMART의 기능을 위한 것입니다(이에 대해서는 나중에 설명하겠습니다). 통계에 따르면 예측된 고장의 수가 20% 미만이었습니다. 이 단계의 기술은 완벽함과는 거리가 멀지만, 혁명적인 한 걸음을 내디뎠습니다.
SMART 개발의 두 번째 단계인 SMART II에 대해서는 알려진 바가 거의 없습니다. 기본적으로 첫 번째와 동일한 문제가 관찰되었습니다. 혁신은 유휴 시간 동안 자동 모드에서 디스크에 의해 수행되는 표면의 배경을 확인하는 기능과 오류 로그의 유지 관리, 모니터링되는 매개변수 목록이 확장되었다는 것입니다(모델 및 제조업체에 따라 다름). 통계에 따르면 예측된 고장의 수가 50%에 도달했습니다.
현대 무대는 SMART III 기술로 대표됩니다. 더 자세히 설명하고 일반적으로 작동 방식, 필요한 항목 및 이유를 이해하려고 노력합시다.
SMART가 드라이브의 기본 특성을 모니터링한다는 것을 이미 알고 있습니다. 이러한 매개변수를 속성이라고 합니다. 모니터링에 필요한 매개변수는 제조업체에서 결정합니다. 각 속성에는 일종의 값(값)이 있습니다. 일반적으로 범위는 0에서 100(최대 200 또는 최대 255일 수 있음)이지만 그 값은 일부 참조 값(제조업체에서 결정)과 관련된 특정 속성의 신뢰도입니다. 값이 높으면 이 매개변수에 변화가 없거나 값에 따라 천천히 저하됨을 나타냅니다. 낮은 값은 급격한 성능 저하 또는 임박한 고장 가능성을 나타냅니다. Value 속성의 값은 높을수록 좋습니다. 일부 모니터링 프로그램은 원시 또는 원시 값을 표시합니다. 이는 드라이브에 저장된 내부 형식(다른 모델 및 제조업체의 드라이브에도 다름)의 속성 값입니다. 단순한 사용자의 경우 정보가 많지 않으며 여기서 계산된 값이 더 중요합니다. 각 속성에 대해 제조업체는 드라이브의 오류 없는 작동이 보장되는 가능한 최소 값(임계값)을 정의합니다. 속성 값이 Threshold 값보다 낮으면 오작동 또는 완전한 고장일 가능성이 매우 높습니다. 속성이 중요하고 중요하지 않다는 점만 추가하면 됩니다. 임계 매개 변수가 임계 값을 초과한다는 사실은 실패를 의미하며 중요하지 않은 매개 변수의 허용 가능한 값 범위를 벗어남은 문제를 나타내지 만 디스크는 작동성을 유지할 수 있습니다 (아마도 일부 특성: 성능, 예).
가장 일반적으로 관찰되는 중요한 특성은 다음과 같습니다. 원시 읽기 오류율 - 디스크에서 데이터를 읽을 때 발생하는 오류율로, 그 출처는 디스크의 하드웨어입니다.
스핀업 시간- 디스크 팩을 정지 상태에서 작동 속도로 회전시키는 데 걸리는 시간. 정규화된 값(Value)을 계산할 때 실제 시간은 공장에서 설정된 일부 기준 값과 비교됩니다. Spin Up Retry Count Value = max(Raw는 0임)의 비저하가 아닌 최대 값은 나쁜 의미가 아닙니다. 참조 시간과의 시간 차이는 전원 공급 장치 고장과 같은 여러 가지 이유로 인해 발생할 수 있습니다.
스핀업 재시도 횟수- 첫 번째 시도가 실패한 경우 디스크를 작동 속도까지 회전시키려는 재시도 횟수입니다. 0이 아닌 원시 값(각각 최대가 아닌 값)은 드라이브의 기계적 부분에 문제가 있음을 나타냅니다.
탐색 오류율- 헤드 블록 위치 지정 오류의 빈도. Raw 값이 높으면 서보 태그 손상, 디스크의 과도한 열 팽창, 위치 지정 장치의 기계적 문제 등이 발생할 수 있는 문제가 있음을 나타냅니다. 값이 일정하게 높으면 모든 것이 정상임을 나타냅니다.
재 할당 섹터 수- 섹터 재할당 작업의 수. 현대의 SMART는 해당 섹터의 안정성을 즉석에서 분석하고, 불량으로 인식되면 재할당할 수 있습니다. 아래에서 이에 대해 더 자세히 이야기하겠습니다.
말하자면 중요하지 않은 정보 속성 중에서 다음이 일반적으로 관찰됩니다.
발생하는 모든 오류 및 매개변수 변경 사항은 SMART 로그에 기록됩니다. 이 기능은 이미 SMART II에 등장했습니다. 잡지의 모든 매개 변수 - 목적, 크기, 번호는 하드 드라이브 제조업체에서 결정합니다. 현재 우리는 그들의 존재 사실에만 관심이 있습니다. 세부 사항 없이. 로그에 저장된 정보는 상태를 분석하고 예측하는 데 사용됩니다.
세부 사항에 대해 설명하지 않고 SMART의 작업은 간단합니다. 드라이브 작동 중에 발생하는 모든 오류 및 의심스러운 현상은 단순히 추적되어 해당 속성에 반영됩니다. 또한 SMART II부터 많은 드라이브에 자가 진단 기능이 있습니다. SMART 테스트는 오프라인, 즉 드라이브가 언제든지 명령을 수락하고 실행할 준비가 되어 있기 때문에 테스트가 실제로 백그라운드에서 수행되고 단독 모드인 오프라인 테스트가 실행될 수 있습니다. 실행이 종료됩니다.
자체 테스트에는 오프라인 수집, 단기 자체 테스트, 확장 자체 테스트의 세 가지 유형이 있습니다. 마지막 두 개는 백그라운드와 배타적 모드 모두에서 실행할 수 있습니다. 여기에 포함된 테스트 세트는 표준화되지 않았습니다.
실행 기간은 몇 초에서 몇 분, 몇 시간이 될 수 있습니다. 갑자기 디스크에 액세스하지 않고 동시에 작업 부하 동안과 같이 사운드를 게시하면 내성적인 것처럼 보입니다. 이러한 테스트에서 수집된 모든 데이터는 로그 및 속성에도 저장됩니다.
그 불량 섹터 ...
이제 모든 것을 시작한 불량 섹터에 대한 질문으로 돌아갑니다. SMART III에는 사용자가 BAD 섹터를 투명하게 재할당할 수 있는 기능이 도입되었습니다. 이 메커니즘은 매우 간단하게 작동합니다. 섹터 읽기가 불안정하거나 읽기 오류가 발생한 경우 SMART는 해당 섹터를 불안정 목록에 추가하고 카운터(현재 보류 중인 섹터 수)를 늘립니다. 반복적으로 액세스할 때 문제 없이 섹터를 읽으면 이 목록에서 제외됩니다. 그렇지 않고 기회가 주어지면 디스크 액세스가 없으면 디스크는 주로 의심스러운 섹터의 표면을 자체 검사하기 시작합니다. 섹터가 불량으로 인식되면 백업 표면에서 섹터로 재할당됩니다(RSC가 그에 따라 증가함). 이러한 백그라운드 재할당은 최신 하드 드라이브에서 서비스 프로그램으로 표면을 확인할 때 불량 섹터가 거의 보이지 않는다는 사실로 이어집니다. 동시에 불량 섹터가 많기 때문에 재할당이 무한정 발생할 수 없습니다. 첫 번째 한계는 분명합니다. 예비 표면의 부피입니다. 이것은 내가 염두에 두었던 경우입니다. 두 번째는 그렇게 분명하지 않습니다. 사실 최신 하드 드라이브에는 P-list(기본, 공장) 및 G-list(작동 중에 직접 형성되는 성장)의 두 가지 결함 목록이 있습니다. 그리고 많은 재할당으로 인해 G-list에 새로운 재할당을 기록할 공간이 없는 것으로 판명될 수 있습니다. 이러한 상황은 SMART에서 높은 비율로 재할당된 섹터로 식별할 수 있습니다. 이 경우 모든 것이 손실되지는 않지만 이는 이 기사의 범위를 벗어납니다.
따라서 SMART 데이터를 사용하면 디스크를 작업장에 가져가지 않아도 디스크에 어떤 일이 발생하는지 상당히 정확하게 말할 수 있습니다. 디스크 상태를 훨씬 더 정확하고 실질적으로 오작동의 원인으로 결정할 수 있게 해주는 다양한 SMART 애드온 기술이 있습니다. 이러한 기술에 대해서는 별도의 기사에서 설명하겠습니다.
드라이브에서 발생하는 모든 문제를 인식하기 위해서는 SMART로 드라이브를 구입하는 것만으로는 충분하지 않다는 것을 알아야 합니다. 물론 디스크는 외부의 도움 없이 상태를 모니터링할 수 있지만 위험이 임박한 경우 자체적으로 경고할 수는 없습니다. SMART 데이터를 기반으로 경고를 발행할 수 있는 무언가가 필요합니다. (일반적인 체인은 아래 그림과 같습니다).
옵션으로 해당 옵션이 활성화된 상태로 부팅할 때 SMART 드라이브의 상태를 확인하는 BIOS가 가능합니다. 그리고 디스크 상태를 지속적으로 제어하려면 일종의 모니터링 프로그램을 사용해야 합니다. 그러면 상세하고 편리한 형태로 정보를 볼 수 있습니다.

DOS를 실행하는 HDD Speed의 SmartMonitor

Windows에서 실행되는 SIGuiardian
우리는 또한 별도의 기사에서 이러한 프로그램에 대해 이야기할 것입니다. 이것은 처음에 SMART와 함께 하드 드라이브를 사용할 때 필요한 요구 사항이 충족되지 않았다고 말할 때 염두에 두었던 것입니다.
정보 저장 기술:
노이즈가드 기술자기 광학 기술
최근 몇 년 동안의 모든 최신 드라이브에서 절대적으로 모든 제조업체에는 드라이브 작동과 매우 밀접하게 관련된 하드 디스크의 SMART 시스템(자체 모니터링, 분석 및 보고 기술)이 있습니다.
최신 SMART 기술은 디스크 상태의 다양한 매개 변수를 모니터링하고 읽을 수 없는 섹터를 추가로 자동 교체하여 하드 디스크 표면을 스캔하고 소위 오류 로그에 입력합니다. 이러한 섹터의 수가 테이블 형식으로 저장된 목록, 오류 로그에서 "신뢰할 수 없는" 섹터의 주기적 재검색, 시스템이 이 섹터가 정상이라고 판단하면 이 목록에서 제외하고 다음이 됩니다. 사용자 정보를 위해 표면에서 사용 가능(그러나 다음 표면 스캔에서 추가 재검사를 위해 표시됨) 또는 섹터가 연속으로 여러 번 읽히지 않으면 다시 쓰지 않고 다음 결함 목록으로 보내집니다. 제조업체마다 이름이 다르지만 목적은 같습니다. 이 시트는 오류 로그 테이블과 최종 G 목록 사이의 중개자 역할을 하며 결함이 이미 G 목록에 영원히 입력될 것입니다. SMART에서 현재 보류 중인 섹터/오프라인 UNC 섹터 라인에 표시됩니다.
현재 보류 상태에서 손상된 섹터는 "생존성"에 대한 다음 재검토 후 읽기/쓰기가 통과하지 못한 경우 최종적으로 재할당된 상태로 보내져 그대로 유지됩니다. 디스크는 추가 작업에 사용하지 않으며 읽기/쓰기를 위해 다시 테스트하지 않습니다.
재할당된 섹터 카운트 라인이 N에서 N + 1로 변경됩니다.
드라이브가 이미 심각하게 손상된 경우 컴퓨터가 부팅될 때 "스마트 상태 불량 백업 및 교체" 메시지가 나타날 수 있습니다. 이것은 하드 디스크의 SMART 상태가 GOOD에서 BAD로 변경되었으며 디스크에 BAD 블록이 적어도 있고 디스크가 계속 악화되고 있음을 의미합니다. 사용자는 데이터를 읽을 수 있는 경우 저장하고 하드 디스크를 새 것으로 교체하는 것이 좋습니다.
스마트한 모습:
다음 열이 있는 테이블로 표시됩니다.
ID - 매개변수 식별 번호
이름 - 프로그램에 의해 표시되는 매개변수의 이름
VAL - Normalized values (Normalized는 이 경우 내부(RAW) VALUE 매개변수가 보다 편리하고 이해하기 쉬운 보기를 위해 특정 알고리즘에 따라 변환되었음을 의미합니다. EG 내부 매개변수의 값은 항상 증가하고 다음 값을 취할 수 있습니다. 수천 단위 및 출력 값 100에서 0으로 변경하고 매개 변수를 출력으로 변경하는 내부 범위를 표시하며 이 경우에는 정상화)
Wrst - 일정 기간 동안 매개변수의 최악의 값
임계값 - 디스크 교체를 권장하는 임계값
스마트 시스템에서 매개변수가 무엇인지 생각해 봅시다. 모니터링 매개변수 세트는 디스크 제조업체에 따라 다르며 나열된 모든 매개변수가 귀하의 경우에 존재하는 것은 아닙니다.
스마트 속성:
1 원시 읽기 오류율 - 플래터에서 섹터를 읽을 때의 오류 수입니다.
2 처리량 성능 - 상대적 단위의 전체 디스크 성능입니다.
3 스핀업 시간 - 0에서 공칭 회전 속도까지 플레이트의 스핀업 시간(밀리초)
4 회전 횟수 - 플레이트의 회전/정지 주기 횟수; 제한된 수의 시작/중지 주기로 인해 디스크의 기계적 수명을 반영합니다.
5 재할당된 섹터 수 - 매개변수는 예비 섹터 수를 반영합니다. 디스크가 읽기/쓰기/검사 오류를 발견하면 예비 영역에서 불량 섹터를 양호한 섹터로 재할당합니다. 속성의 정규화 값은 예비 섹터가 감소함에 따라 감소합니다. RAW 값은 일반적으로 0이어야 하는 사전 할당된 섹터 수를 나타냅니다. SSDRAW에서 값은 불량 플래시 블록의 수를 나타냅니다.
6 읽기 채널 여백 - 이 속성은 최신 드라이브에서 사용되지 않습니다.
7 탐색 오류율 - 헤드 위치 오류의 수.
8 탐색 시간 성능 - 지정된 섹터에 대한 자기 헤드 드라이브의 평균 위치 지정 속도. 매개변수는 SSD에서 사용되지 않습니다.
9 전원 켜기 시간 - 전원 켜기 상태에서 소요된 시간을 기준으로 한 디스크의 예상 수명. 정규화 된 값은 디스크 리소스와 관련하여 100에서 0으로 감소합니다. 이 매개변수의 감소는 디스크 역학의 상태를 간접적으로 나타냅니다.
10 스핀업 재시도 - 첫 번째 시도가 실패한 경우 플레이트를 회전시키려는 시도 횟수. 사용 시작 순간부터 고려됩니다. SSD에서 사용되지 않음
12 시작/중지 횟수 - 플레이트의 시작/중지 횟수를 기반으로 한 예상 수명; 각 디스크에는 제한된 수의 시작 / 중지가 있으며 매개 변수는 100에서 0으로 감소합니다. RAW 값은 켜짐/꺼짐 횟수를 나타냅니다.
13 소프트 읽기 오류율 - 일부 제조업체는 이 매개변수를 ECC에 의해 복구되지 않은 오류 수를 나타내는 것으로 설명하지만 다른 제조업체는 반대로 복구합니다.
100 지우기/프로그램 주기 - 전체 수명 동안 전체 플래시 메모리에 대한 총 읽기/쓰기 주기 수. SSD에는 읽기/쓰기 주기 수에 제한이 있으며 특정 값은 플래시 메모리 칩의 유형 및 제조업체에 따라 다릅니다.
103 Translation Table Rebuild - 블록 주소의 내부 테이블이 손상 및 복원되었을 때 재구축하는 이벤트의 수. RAW 값은 이벤트 데이터의 실제 양을 나타냅니다.
170 예약된 블록 수 - SSD의 예비 블록 풀 상태를 설명하고 나머지 블록의 백분율을 보여줍니다. RAW 값은 때때로 사용된 예비 블록의 수를 나타냅니다.
171 Program Fail Count - 플래시 메모리 블록 쓰기에 실패한 경우의 수
172 Erase Fail Count - 플래시 메모리 블록의 지우기 작업이 실패한 경우의 수
173 Wear Leveler Worst Case Erase Count - 플래시 메모리 블록에서 수행되는 최대 삭제 횟수
178 사용된 예약 블록 수 - SSD의 예비 블록 풀 상태를 설명하고 나머지 블록의 백분율을 표시합니다. RAW 값은 때때로 사용된 예비 블록의 수를 나타냅니다.
180 Unused Reserved Block Count - SSD의 예비 블록 풀 상태를 설명하고 나머지 블록의 백분율을 보여줍니다. RAW 값은 때때로 사용되지 않은 예비 블록의 수를 나타냅니다.
183 SATA Downshifts - 성공적인 데이터 전송을 위해 SATA 전송 속도(6Gb/s에서 3Gb/s 또는 1.5Gb/s로)를 낮추어야 하는 빈도를 보여줍니다. 속성 값이 감소하면 케이블을 교체해야 합니다.
184 End-to-End 오류 - 디스크 버퍼에서 발생한 오류 수. HP SMART IV 기술의 일부입니다. 디스크 RAM 버퍼의 오작동을 나타낼 수 있습니다.
185 머리 안정성 - 속성에 대한 신뢰할 수 있는 정보가 없습니다.
186 Induced Op-Vibration Detection - 속성에 대한 신뢰할 수 있는 정보가 없습니다.
187 보고된 UNC 오류 - 수정되지 않은 읽기 오류 수
188 명령 시간 초과 - 시간 초과로 인해 디스크에서 실행되지 않은 명령 수
189 High Fly writes - 표면 위의 자기 헤드의 잘못된 비행 높이로 인해 발생하는 쓰기 오류 수
190 기류 온도 - HDA 내부의 공기 온도
191 G-Sense 오류 - 충격이나 진동으로 인해 드라이브가 작업을 중단한 횟수를 나타냅니다.
192 power-off retract cycles - 디스크를 끄라는 명령이 수신되기 전에 손실된 예기치 않은 정전 횟수. HDD는 예기치 않은 종료의 경우 평소보다 수명이 훨씬 짧습니다. ssd는 예기치 않은 정전이 있을 때 내부 상태 테이블을 잃을 위험이 있습니다.
193 로드/언로드 사이클 - 주차 영역과 데이터 영역 사이의 BMG 이동 횟수. 값은 100에서 0으로 감소하고 raw는 실제 이동 횟수를 포함합니다.
194 hda 온도 - 자기 헤드 유닛의 온도
195 하드웨어 ecc가 복구됨 - 오류 수정 코드로 수정된 읽기 오류 수
196개의 재할당 이벤트 - 총 섹터 재할당 횟수, 오프라인 검색 및 정상 작동 모두 포함
197 현재 보류 중인 섹터 - 재확인 및 재할당 대기 중인 불안정한 섹터의 수
198 오프라인 스캔 unc 섹터 - 백그라운드 자체 스캔 중에 디스크에서 발견한 불량 섹터 수. 이 매개변수의 열화는 표면의 급격한 열화를 나타냅니다.
199 ultra dma crc 오류 - 디스크와 디스크 간에 데이터를 전송할 때 발생하는 오류 수 마더보드; 이 매개 변수가 악화되면 케이블을 교체하는 것이 좋습니다.
200 쓰기 오류율 - 쓰기 시 오류 빈도
202 데이터 주소 표시 오류 - 요청된 섹터 검색 시 오류 수
203 run out cancel - 오류를 수정하려고 할 때 잘못된 체크섬으로 인해 발생한 오류 수
204 소프트 ecc 수정 - 수정 코드로 수정된 오류 수
206 비행 높이 - 최적 값에 대한 표면 위의 헤드 비행 높이 편차. 헤드가 너무 낮으면 표면이 손상될 수 있으며 너무 높으면 읽기 오류 수가 증가합니다.
207 스핀 고전류 - 판을 회전시키는 데 필요한 전류의 양
209 오프라인 검색 성능 - 오프라인 검색을 수행할 때 검색 하위 시스템의 성능
220 디스크 이동 - 기계적 손상 또는 과열의 결과로 이론적인 위치에 비해 플레이트 팩이 이동한 거리
227 토크 증폭 횟수 - 플레이트를 풀기 위해 증가된 전류를 적용하는 데 필요한 횟수를 보여줍니다.
230gmr 헤드 진폭
233 미디어 마모 표시기 - ssd의 남은 메모리 리소스
240 헤드 비행 시간 - 헤드가 사용자 데이터 영역에서 보낸 시간. 값은 일반적으로 100에서 0으로 감소합니다.
241 쓰기된 총 lbas - 장치 수명 동안 쓰여진 512바이트 블록 수
242 총 lbas 읽기 - 장치의 전체 수명 동안 읽은 512바이트 블록 수
250 읽기 오류 재시도 비율
스마트 값 해석의 어려움은 모니터링되는 매개변수의 수량, 유형, 값 및 측정 단위에 대한 단일 표준이 없다는 것입니다. 따라서 스마트 구현은 항상 공급업체에 따라 다릅니다. 원시 값을 속성 표시기로 정규화하는 것은 다르게 수행되며 결과는 스마트 양호 또는 불량 검사 상태입니다. 따라서 디스크 상태에 대한 신뢰할 수있는 결론은 진단 프로그램으로 표면을 확인해야만 가능합니다. 그러나 디스크의 상태와 가능한 문제를 신속하게 평가해야 하는 경우 몇 가지 기본적이고 가장 유익한 속성에 주의를 기울여야 합니다.
가장 중요한 스마트 속성:
5 재할당된 섹터 수 - 재할당된 섹터 수 이 속성 값의 증가는 디스크 표면 상태의 악화를 나타냅니다.
05. 08.2017
Dmitry Vassiyarov의 블로그.
SMART HDD 판독값 - 무엇이며 그 이유는 무엇입니까?
안녕하세요 친구. 미래를 내다보고 컴퓨터의 하드 드라이브가 언제 고장날지 알고 싶습니까? 이것은 가능하며 점쟁이가 아니라 SMART HDD 기술을 개발한 과학자들 덕분입니다. 이제 디스크가 긴밀하게 제어됩니다.
하드 드라이브는 일반적으로 수년간 축적된 정보를 저장하기 때문에 상태를 모니터링하는 것이 매우 중요합니다. 하드 드라이브가 소유자에게 갑자기 고장나서 파일을 복구할 수 없는 경우가 종종 있습니다.
이러한 일이 발생하지 않도록 하려면 이 기사를 읽으십시오. SMART가 무엇인지, 누가 사용할 수 있는지, 어떻게 하는지, 많은 추가 유용한 정보를 배우게 됩니다.
복명
조금이라도 익숙한 사람들은 영어"스마트"하기 때문에 기술을 SMART라고 생각할 수도 있습니다. 이 경우 그러한 번역은 적절하지 않습니다.
이것은 번역에서 "자체 모니터링, 분석 및보고 기술"을 의미하는 "자체 모니터링, 분석 및보고 기술"로 해석되는 약어입니다.
이것에서 하드 드라이브와 관련된 목적에 대해 스스로 결론을 내릴 수 있습니다. 그러나 기술은 각각 구현되지 않고 SATA 프로토콜을 지원하는 경우에만 구현됩니다. 대체로 이들은 모두 현대적인 모델입니다.

등장의 역사
IBM은 1992년 처음으로 유사한 기술의 하드 드라이브를 출시했습니다. 시스템의 기능은 훨씬 적었지만 아이디어는 좋았습니다. 따라서 Seagate, Quantum, Conner 및 Compaq은 유사한 기술을 개발했습니다.
앞으로이 목록의 마지막 회사는 제품 표준화를 제안했으며 그 결과 나열된 모든 브랜드는 Western Digital과 함께 SMART HDD 기술을 세계에 도입했습니다.
첫 번째 버전은 하드 드라이브의 주요 매개변수 분석을 위해 제공되었으며 명령에 의해서만 적용되었습니다. Hitachi는 HDD의 내성이라는 아이디어를 내놓은 2세대 개발에도 참여했습니다. SMART 3에는 결함을 감지하고 수정하는 옵션이 추가되었습니다.
SMART는 무엇을 할 수 있습니까?
위에서 우리는 이미이 주제에 대해 조금 다루었으므로 이제 더 자세히 설명하겠습니다. 이 기술을 사용하여 드라이브의 현재 상태를 진단할 수 있습니다. 테스트 결과에 다음이 표시됩니다.
- 재할당된 섹터의 수
- 검색 속도를 추적하십시오.
- 켜기 및 끄기 주기의 수입니다.
- 이 과정에서 생성된 오류의 수 및 훨씬 더.
또 다른 유용한 SMART 옵션은 읽을 수 없는 섹터의 자동 교체입니다. 그녀는 그것들을 소위 오류 로그에 기록합니다. 테이블.
스캔할 때마다 이러한 셀이 다시 확인됩니다. 작동하는 것으로 판명되면 시스템은 해당 항목을 목록에서 제외하고, 그렇지 않은 경우 다른 결함 목록으로 이동한 후 섹터를 더 이상 사용하지 않습니다.
SMART hdd는 시스템 구성 요소를 모니터링하는 것 외에도 하드 드라이브의 물리적 상태를 평가하므로 오류 시간을 예측할 수 있습니다. 너는 볼 수있어:
- 헤드가 이동하고 스핀들이 회전한 횟수;
- 하드 드라이브 등의 표면 위의 헤드 높이는 얼마입니까?
따라서 물리적 매개변수 중 하나라도 표준과 일치하지 않으면 기술에서 이에 대해 알려줍니다.
그러나 전압 서지나 충격으로 인한 하드 드라이브의 손상은 예측할 수 없다는 점에 유의하십시오.

필요한 소프트웨어
SMART HDD가 작동하려면 이를 지원하는 하드 드라이브만 있으면 충분하지 않습니다. 추가로 하드 드라이브 컨트롤러에 내장된 소프트웨어와 통신하는 데 사용할 특수 프로그램을 설치해야 합니다.
데이터를 얻을 수는 있지만 해독하기 어려울 것입니다. 그리고 이러한 목적을 위해서는 특별한 소프트웨어가 필요합니다. 테스트 결과는 어떻게 보나요? 여기 몇 가지 예가 있어요.
빅토리아.
나는 이미 그녀에 대해 이야기했습니다. 사용하기 위해 비용을 지불할 필요가 없는 가장 인기 있는 옵션 중 하나입니다. 유틸리티를 시작한 후 "Standart" 탭에서 확인할 나사를 선택하고 "Smart" 메뉴로 전환한 다음 "Get" 버튼을 누릅니다. HDD의 상태는 레벨 및 색상 표시기로 표시됩니다.

공식 링크는 다음과 같습니다. //crystalmark.info/redirect.php?product=CrystalDiskInfoInstaller
가장 편리하고 또한 자유로운 길인터페이스가 간단하고 언어를 러시아어로 변경할 수 있으므로 나사를 조사하십시오. 상단에 있는 같은 이름의 탭에서 디스크를 선택하면 모든 매개변수가 아래에 펼쳐집니다. 
그건 그렇고, 이미 Windows 7에서 SMART HDD 지원이 컴퓨터 관리 스냅인에 도입되었습니다. 특히 디스크 검사는 시스템 상태 정보의 기본 수집기입니다.

결과 디코딩
시스템은 원시 값이라고 하는 16진수 형식으로 정보를 저장합니다. 데이터는 표준에 따라 하드 드라이브의 신뢰성을 표시하는 값 매개변수로 포맷됩니다.
등급은 주로 0에서 100까지의 척도로 이루어 지지만 일부 항목은 0에서 253까지 측정됩니다. 높은 숫자는 정상 상태를 나타내고 낮은 숫자는 임박한 고장 가능성을 나타냅니다. 결과가 프로펠러 제조업체가 문제 없는 작동을 보장하는 최소값보다 적으면 조립품이 고장난 것입니다.
어떻게 생겼나요?
프로그램은 여러 필수 필드로 나누어진 테이블 형식으로 결과를 표시합니다.
- ID(Num) - 매개변수 식별 번호.
- 이름 - 설명;
- VAL - 디스크 상태를 나타내는 숫자(위에서 언급한 대로).
- Wrst(최악) - 하드 역사상 최악의 가치.
- 임계값(Threshold) - 나사가 실패하는 숫자입니다.

스마트 속성
"이름" 목록에서 각각의 특정 하드 매개변수를 담당하는 많은 속성을 찾을 수 있습니다. 모두 길고 나열할 필요가 없습니다. 주로 무엇을 찾아야 하는지 고려하십시오.
- (5) 재할당된 섹터 수. HDD에 재할당된 슬롯의 수를 표시합니다.
- (7) 오류율을 구합니다. 여기에서 자기 헤드 어셈블리(MRU)의 위치 지정이 발생하는 빈도를 확인할 수 있습니다.
- (11) 재보정 재시도. BMG 보정에 실패한 시도 횟수를 제공합니다.
- (184) 종단 간 오류입니다. 드라이브 버퍼의 오류 수를 나타냅니다.
- (187) 수정할 수 없는 오류가 보고되었습니다. 장치의 펌웨어가 수정할 수 없는 오류 수입니다.
- (191) G 감지 오류율. 충격으로 인해 나사가 오작동하는 횟수를 알려줍니다. 매개변수는 내부 가속도계에 의해 결정됩니다.
- (197) 현재 보류 중인 섹터 수. 곧 작동을 멈출 수 있는 불안정한 섹터를 표시합니다.
- (198) 수정 불가능한 섹터 수. 수정할 수 없는 오류의 카운터로 번역됩니다.
- (199) UltraDMA CRC 오류 카운트. 디스크에서 컴퓨터로 데이터를 전송하는 동안 발생한 오류를 계산합니다. 숫자가 증가하면 케이블을 교체해야 합니다.
그건 그렇고, 시스템은 종종 하드 드라이브의 노후화 때문이 아니라 갑작스런 전원 끄기 또는 케이블 결함으로 인해 불량 섹터를 감지합니다. 그러나 실제로 이러한 블록은 매우 효율적입니다. 이러한 경우 속성 재설정을 수행할 수 있지만 이 프로세스는 전문가에게 맡기는 것이 가장 좋습니다.
테스트 옵션
SMART 시스템은 여러 유형의 테스트를 수행할 수 있습니다.
- 짧은. 약 2분 동안 지속됩니다. 전기, 기계 및 읽기 성능 검사가 수행됩니다.
- 긴 / 확장. 리드 타임: 2-3시간. 하드 드라이브의 표면이 평가됩니다.
- 선택적. 드라이브의 개별 구성 요소를 연구해야 합니다.
- 전달 테스트. 오래 걸리지 않습니다. 공급자로부터 사용자에게 운송된 후 장치의 상태를 분석하는 데 필요합니다.
그게 다야.
테스트 결과가 긍정적이도록 하십시오.

 가격 대비 성능이 가장 좋은 저렴하고 좋은 노트북을 선택하는 방법은 무엇입니까?
가격 대비 성능이 가장 좋은 저렴하고 좋은 노트북을 선택하는 방법은 무엇입니까? Pokhlebaev mikhail ivanovich 어떤 종류의 건설 현장
Pokhlebaev mikhail ivanovich 어떤 종류의 건설 현장 맥심 택시 앱 맥심 택시 앱 다운로드
맥심 택시 앱 맥심 택시 앱 다운로드 맥심택시 어플리케이션 맥심택시 어플리케이션 다운로드 프로그램
맥심택시 어플리케이션 맥심택시 어플리케이션 다운로드 프로그램