프로세서 및 비디오 카드를 로드하기 위한 유틸리티입니다. 최고의 무료 시스템 리소스 모니터
이전 기사에서는 Linux 시스템을 모니터링하기 위한 80가지 도구 목록을 컴파일했습니다. 또한 Windows 시스템용 도구를 선택하는 것이 합리적이었습니다. 아래 목록은 시작점일 뿐 순위는 없습니다.
1.작업관리자

그래야만 관리자가 필요한 조치를 취할 수 있습니다. 결국, 하드웨어 제어를 추가하지 않고도 상황을 복잡하게 만들 만큼 이미 충분히 불이 붙었습니다. 하드 드라이브가 원활하게 실행되고 프린터가 준비되어 있어야 하며 모든 장치가 안정적으로 작동해야 합니다. 하드웨어 모니터링 소프트웨어는 백그라운드에서 안정적으로 실행되어 관리자의 작업을 더 쉽게 만듭니다.
즉각적인 장비 제어
보장하는 마음의 평화
Steffen Ihl, 바우하우스-바이마르 대학. 단순함을 최우선으로, 지금 그리고 영원히. 모니터링을 설정하는 데 몇 분 정도 걸립니다. 24시간 편리한 장비와 네트워크 모니터링. 직관적인 웹 인터페이스 디자인을 엽니다. 통합 알림 기능은 문제 또는 시스템 오류를 즉시 보고합니다.유명한 디스패처 Windows 작업- 실행 중인 프로세스 및 이들이 소비하는 리소스 목록을 표시하는 유틸리티. 하지만 그 잠재력을 최대한 활용하는 방법을 알고 있습니까? 일반적으로 프로세서와 메모리의 상태를 제어하지만 훨씬 더 멀리 갈 수 있습니다. 이 응용 프로그램은 모든 운영 체제에 사전 설치되어 있습니다. 마이크로소프트.
고객의 79%는 네트워크 관리에서 상당한 또는 심지어 탁월한 비용 절감 효과를 발견했습니다. 고객의 경험에 따르면 비용은 평균 3개월 반 이내에 상환되었습니다. 문제가 긴급해지기 전에 알림을 받을 수 있으므로 문제를 해결할 시간이 있습니다. 당신에게 절대적인 마음의 평화를 주는 것은 바로 이 보안입니다.
지금이 가장 중요한 순간이다
직관적인 웹 인터페이스는 모든 센서 데이터에 대한 개요를 제공합니다. 이동하는 방법을 이해하는 것이 점점 쉬워집니다. 장비 관리에 소요된 시간을 이제 다른 작업에 사용할 수 있습니다. 마지막으로, 일상 활동에 시간을 낭비하지 않고 새롭고 특이한 프로젝트에 전념하고 새로운 도전에 직면할 수 있습니다.
2. 리소스 모니터
CPU 사용량을 평가하는 훌륭한 도구, 랜덤 액세스 메모리, Windows의 네트워크 및 드라이브. 이를 통해 중요한 서버의 상태에 대해 필요한 모든 정보를 신속하게 얻을 수 있습니다.

3.성능 모니터
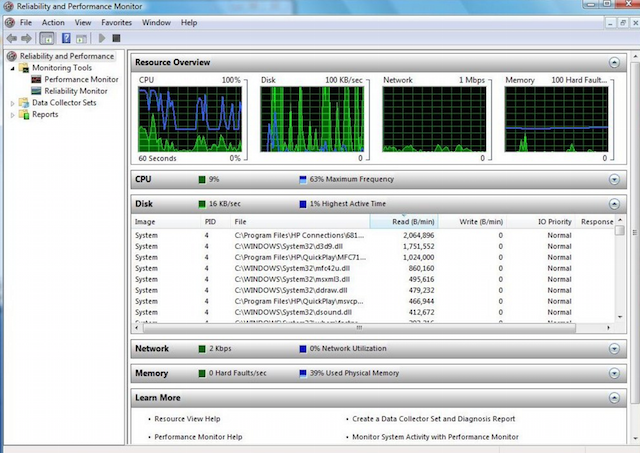
개요 덕분에 필요할 때 하드웨어를 빠르게 확장하고 새 제품을 구입할 수 있습니다. 하드 드라이브기존 기기가 만차되기 전에 기기를 적시에 교체하여 실제 필요에 따라 구매하므로 비용을 절감할 수 있습니다.
즉각적인 경고 시스템
이런 식으로 당신은 당신의 일의 가치를 지지하는 지도자들에게 올바른 주장을 할 수 있을 것입니다. 각 사람에게 알리는 시간과 방법을 지정할 수 있습니다. 이렇게 하려면 언제든지 연락처를 추가하거나 알림을 편집, 삭제 또는 일시 중지할 수 있습니다.
Windows에서 성능 카운터를 관리하기 위한 기본 도구입니다. 성능 모니터, 이전 Windows 버전시스템 모니터로 알려져 있습니다. 이 유틸리티에는 여러 표시 모드가 있고, 실시간으로 성능 카운터를 표시하고, 나중에 연구할 수 있도록 데이터를 로그 파일에 저장합니다.
통합된 알림 시스템 소프트웨어모니터링을 위해 추가 비용 없이 사용할 수 있습니다. 통합 덕분에 몇 번의 클릭만으로 알림 기능을 설정할 수 있습니다. 통과된 각 임계값에 대해 관련 알림이 전송됩니다. 이를 통해 고객과 사용자가 문제를 찾기 전에 신속하게 개입할 수 있습니다.
매일 우리의 목표는 힘을 최대화하는 것입니다. 고객을 위한 소프트웨어 사용 용이성. 물론, 우리는 우리의 작업에 대해 인정을 받는 것을 자랑스럽게 생각합니다. 이 "5개의 앱" 모임에서 우리는 시스템 모니터 역할을 하는 일부 사용자를 소개합니다. 별도로 다운로드할 수 있는 편리한 위젯도 포함되어 있습니다. 장점: 완전히 완성됨 단점: 빈약한 인터페이스 가격: 무료. . 유료 버전도 있지만 기본 기능은 포함되어 있지 않으며 주로 프로젝트를 지원하기 위한 것입니다.
4.신뢰성 모니터
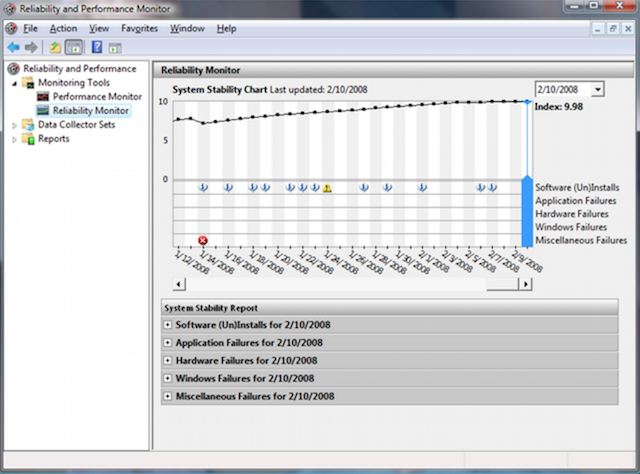
안정성 모니터 - 시스템 안정성 모니터를 사용하면 컴퓨터 성능의 변경 사항을 모니터링할 수 있습니다. Windows 7의 안정성 모니터는 Windows 8: 제어판 > 시스템 및 보안 > 관리 센터에서 찾을 수 있습니다. Reliability Monitor를 사용하면 컴퓨터의 변경 사항과 오류를 추적할 수 있으며 데이터가 편리한 그래픽 형식으로 표시되므로 어떤 응용 프로그램이 오류가 발생하거나 중단되었는지, 모양을 추적할 수 있습니다. 블루 스크린 윈도우 죽음, 출현 이유(또 다른 윈도우 업데이트또는 소프트웨어 설치).
장점: 훌륭한 조직 탭, 기능적인 그래픽, 인터페이스 탭 단점: 말할 것도 없음 가격: 무료 및 194 문지름. 알림 표시줄이나 플로팅 위젯을 통해 일부 값을 볼 수도 있지만 그렇게 해도 UI를 가리는 것은 문제가 되지 않습니다.
배너가 귀찮다면 광고 전에 유료 버전도 있습니다. 커널과 운영 체제는 고급 컴퓨터에서 매우 잘 작동하는 것처럼 보이지만 데스크탑 성능 문제를 일으킬 수 있는 하드웨어 및 소프트웨어 문제가 있을 수 있습니다. 문제가 어디에 있는지 알 수 있는 몇 가지 트릭이 있으며 아마도 해결책을 찾을 수 있을 것입니다. 비즈니스 중에 몇 가지 시나리오로 시작하는 것이 가장 좋다는 것을 이해하지만 이것은 거의 발생하지 않으며 이 모든 작업은 결국 시스템 성능을 저하시킵니다.
5. 마이크로소프트 SysInternals
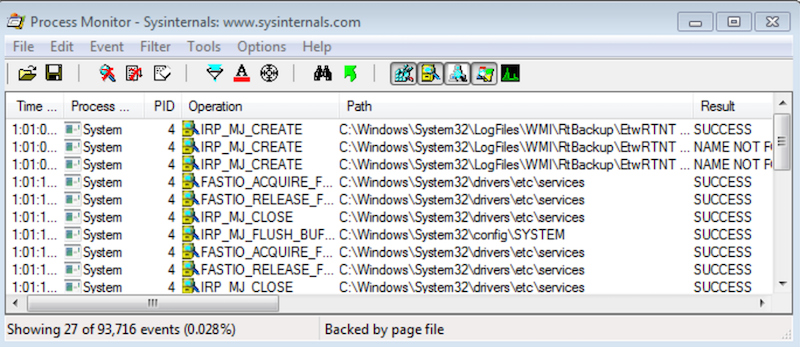
SysInternals는 Windows를 실행하는 컴퓨터를 관리하고 모니터링하기 위한 완전한 프로그램 세트입니다. Microsoft 웹 사이트에서 무료로 다운로드할 수 있습니다. Sysinternals 도구는 응용 프로그램 및 운영 체제를 관리, 문제 해결 및 진단하는 데 도움이 됩니다. 윈도우 시스템.
멀티 코어 프로세서가 있는 시스템의 경우 백분율이 거짓이고 100%를 초과할 수 있습니다. 사실, 상단을 보여주는 것은 두 코어의 합입니다. 도서관을 예로 들어보자. 그 책이 매우 성공적이었고 매우 필요하다고 가정해 봅시다. "매우 편리하지만 소유한 모든 책에 대해 이 작업을 수행할 수는 없습니다." 대부분의 출판물의 경우 다른 잡지에 가서 다른 책, 즉 일반적으로 재고가 있는 잡지를 빌려야 합니다. 대중이 필요로 하는 다양한 책들에 비해 모든 책을 찾는 시간이 늘어나고 응답이 늦어지는 것은 당연하다.
6. SCOM(Microsoft System Center의 일부)

System Center - Microsoft 소프트웨어(Windows, IIS, SQLServer, Exchange 등)를 관리, 배포, 모니터링, 구성할 수 있는 IT 인프라 관리를 위한 완전한 도구 세트입니다. 아아, MSC는 무료가 아닙니다. SCOM은 주요 IT 인프라 개체의 사전 모니터링에 사용됩니다.
사용자가 요청한 책이 수십 권에 달하는 경우 판매자 중 일부는 이 단일 요청을 충족하기 위해 최선을 다하고 있는 것이 분명하므로 다른 요청에서는 사용할 수 없으므로 남자가 무엇을 하는지 아는 것이 중요합니다. 당신의 HDD조정에서 작동하고 그가하는 일을 몰라?
단, 모든 배포판에 제공되는 것은 아니므로 별도로 설치해야 할 수도 있습니다. 저장소에 제공되어야 하지만 그렇지 않은 경우 여기에서 다운로드하십시오. 정상적인 대기 시스템은 아래와 같이 데이터가 디스크에 기록될 때 화면에 긴 0 문자열을 표시해야 하며 때로는 작은 숫자 패드와 함께 표시해야 합니다.
Nagios 제품군으로 Windows 서버 모니터링
7. 나기오스

Nagios는 몇 년 동안(Linux 및 Windows용) 가장 인기 있는 인프라 모니터링 도구였습니다. Windows용 Nagios를 고려 중인 경우 에이전트를 설치하고 구성하십시오. 윈도우 서버. NSClient++는 실시간으로 시스템을 모니터링하고 다음과 같은 출력을 제공합니다. 원격 서버모니터링 등.
지금까지 도구에 대해 알아보았습니다. 명령줄두 가지 주요 이유 때문입니다. 현재 CPU 사용량, 메모리 사용량, 디스크 활동, 그래픽 카드 사용량 등에 대한 개요를 확인합니다. 많은 순간에 매우 유용합니다. 시스템의 개별 프로그램 요구 사항에 대한 아이디어를 얻고 얻은 데이터를 평가하여 미래의 컴퓨팅 성능을 최적화할 수 있습니다.
그들의 토론과 논쟁에 영감을 주어 다운로드하고 테스트할 가장 흥미롭고 인기 있는 프로그램을 제공합니다. 첨부된 설문조사의 팁과 프로그램에 대한 만족도를 표현할 수 있습니다. 유틸리티 유틸리티는 제어, 레이아웃, 설정 및 사용자의 필요에 따라 조정할 수 있는 훌륭한 기회입니다. 모습.
8. 선인장

일반적으로 Nagios와 함께 사용되며 순환 데이터베이스(Round Robin Database)와 함께 작동하도록 설계된 RRDTool 유틸리티에 대한 편리한 웹 인터페이스를 사용자에게 제공합니다. 이 유틸리티는 특정 기간 동안 하나 이상의 값 변경에 대한 정보를 저장하는 데 사용됩니다 기간. 네트워크 장치의 통계는 사용자가 설정한 트리 형태로 제공되며, 채널 사용량, HDD 파티션 사용량, 디스플레이 리소스 대기 시간 등의 그래프를 작성할 수 있습니다.
또한 자체적으로 너무 많은 시스템 리소스를 제공하지 않으며 무료로 사용할 수 있습니다. 공간과 와이드스크린 디스플레이의 적절한 배치를 피할 수 있습니다. 그 목적은 오버클러킹, 오류 감지, 과열 원인 찾기 등에 사용할 수 있는 정보를 얻는 것입니다. 그것은 cpu, 메모리, 온도, 전압 및 건강을 측정할 수 있습니다 운영 체제또한 다양한 벤치마크를 제공합니다.
여기에서 사이드바나 데스크탑의 어느 곳에나 배치할 수 있는 간단한 전력계와 하드웨어 로더를 찾을 수 있습니다. 항상 가까이 있지만 방해가 되지는 않습니다. 그는 단순하고 명확하며 신뢰할 수 있는 것을 좋아합니다. 또한, 만약 새 버전출시되면 앱 자체에서 알려줍니다. 가제트는 사용자 정의가 가능하고 문제가 없다는 Jan Gottwald도 사용합니다.
9. 신켄

유연하고 확장 가능한 오픈 소스 모니터링 시스템 소스 코드, Python으로 작성된 Nagios 커널을 기반으로 합니다. Nagios보다 5배 빠릅니다. Shinken은 Nagios와 호환되며 조정이나 추가 구성 없이 플러그인 및 구성을 사용할 수 있습니다.
또한 멀티 코어 프로세서는 각 코어를 개별적으로 측정하고 프로세서 자체 및 사용에 대한 완전한 정보를 제공합니다. 간단한 작업 관리자에서 알 수 있는 형식으로 작업 및 프로세스 관리를 제공합니다. 물론 문제가 발생하거나 활동이 없다고 보고하는 경우 작업과 프로세스를 모두 비활성화할 수 있습니다. 프로세스의 경우 CPU와 메모리를 얼마나 사용하고 있는지 알 수 있습니다.
우선 순위와 근접성을 지정하고, 프로세스 트리를 종료하거나, 다시 시작하거나, 시작 방법을 설정할 수도 있습니다. 그러나 이 프로그램은 완전한 조수를 만드는 다른 많은 기술도 제공합니다. 창 탭을 전환하여 CPU 성능, 메모리, 네트워크 등을 제어할 수 있습니다. 다른 창에는 서비스 목록이 표시되고, 다른 창에는 현재 인터넷 연결이 표시되며, 창문을 열다또는 편집할 수 있는 실행 중인 응용 프로그램 목록입니다.
10. 아이싱가

호스트 및 서비스를 확인하고 해당 상태를 관리자에게 보고하는 또 다른 인기 있는 개방형 모니터링 시스템입니다. Nagios의 포크인 Icinga는 그것과 호환되며 공통점이 많습니다.
11. 옵스뷰
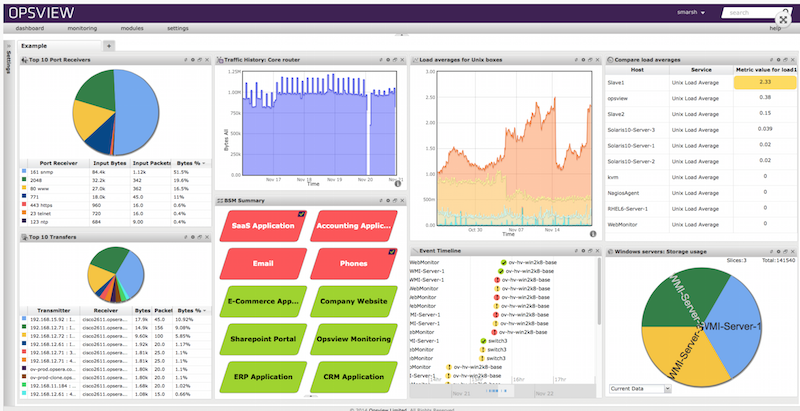
여기서 우리는 작업 관리자의 두 번째 중요한 후계자를 언급할 것입니다. 이 응용 프로그램은 프로세서, 메모리 또는 비디오 카드의 최대 성능을 제공하는 프로세스를 모니터링할 수 있는 두 부분의 조합에 매우 적합합니다. 또한 계속 작업할 수 있는 명확한 일정을 제공합니다. 모든 컴퓨터는 테스트를 거쳐야 하고 오버클럭을 하면 두 배가 됩니다.
온도가 비슷하거나 약간 높으면 캐비닛과 공기 흐름이 잘 설계된 것입니다. 구리 냉각기 냉각은 흥미로운 옵션이지만 냉각에는 실제로 전체 시스템이 필요합니다. 컴퓨터가 이 여러 시간 동안의 테스트를 견디면 오버클럭 및 냉각에 만족할 수 있습니다. 그렇지 않은 경우 주파수를 조정하거나 전력을 높이거나 냉각을 개선해야 합니다. 극도의 부하에서 불안정한 과열된 컴퓨터는 쓸모가 없으며 중요한 작업을 해야 할 때 충돌할 수 있습니다.
OpsView는 처음에 무료였습니다. 이제 이 모니터링 시스템의 사용자는 포크아웃해야 합니다.
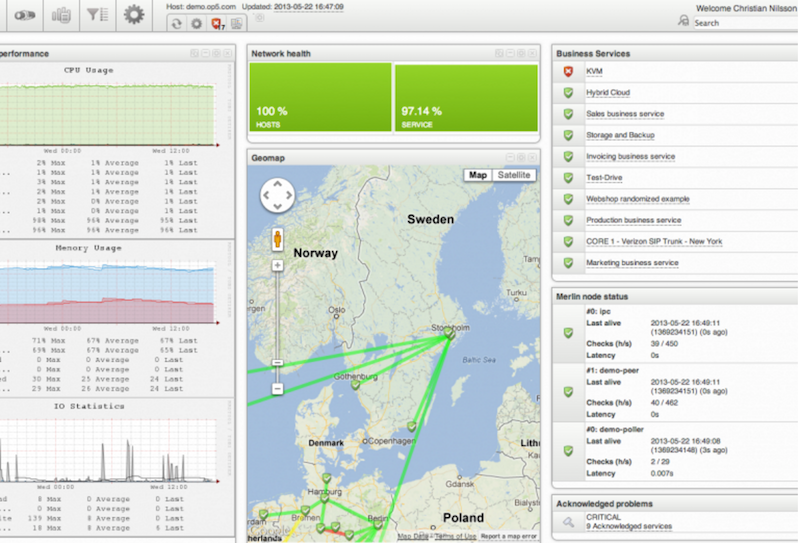
Op5는 또 다른 오픈 소스 모니터링 시스템입니다. 그래프, 데이터 저장 및 수집.
Nagios의 대안
13. 자빅스다양한 서비스의 상태를 모니터링하고 추적하기 위한 오픈 소스 소프트웨어 컴퓨터 네트워크, 서버 및 네트워크 장비는 프로세서 부하, 네트워크 사용량, 디스크 공간 등에 대한 데이터를 얻는 데 사용됩니다.
그러니 실제로 경험하십시오! 그동안 컴퓨터를 제어할 수 있는 경우에도 이러한 유형의 응용 프로그램 중 일부는 매우 유용할 수 있습니다. 또한 가제트의 장점은 명백한 외관과 평범한 설치 과정입니다. 게시자 확인 메시지가 나타나면 설치를 클릭합니다.
"다음"과 "설치"를 차례로 클릭하여 설치 프로세스를 진행합니다. "마침" 버튼을 클릭하여 설치를 완료합니다. 응용 프로그램이 자동으로 시작되고 해당 창이 바탕 화면에 나타납니다. 시스템 트레이 - 프로그램 아이콘에 새 요소가 나타납니다. 침구 시스템 용 트레이이므로이 설정을 변경할 가치가 있습니다. 이렇게 하려면 Core 응용 프로그램 창에서 옵션 탭을 선택합니다. 탭에서 "시스템 트레이" 탭을 선택하십시오.
14. 무닌

동시에 여러 서버에서 데이터를 수집하고 모든 것을 그래프 형태로 표시하는 우수한 모니터링 시스템으로 서버의 모든 과거 이벤트를 추적할 수 있습니다.
15.제노스

새 창에서 "활성 영역 아이콘 표시"를 선택하고 "저장"을 클릭하여 트레이를 재정렬합니다. 그런 다음 옵션 탭을 다시 클릭하고 설정을 선택합니다. 이제 백그라운드에서 프로그램을 실행하면 하나의 편리한 아이콘이 표시됩니다. 이렇게 하려면 가젯을 마우스 오른쪽 버튼으로 클릭하고 탭에서 옵션을 선택합니다.
아래 차트의 마커. 마커를 선택한 다음 비활성화합니다. 채점자. 메모리 사용량 모니터링은 물리적 메모리, 페이지 파일 및 일반적으로 관련이 있습니다. 모니터링 결과는 그래프, 막대, 숫자로 표시되며 프리젠테이션 데이터는 기본 설정에 따라 사용자 지정할 수 있습니다. 이 프로그램을 사용하면 프로세서, 메모리 및 온도와 관련된 개별 구성 요소에 대한 정보를 개별 또는 일반 차트 및 막대에 표시할지 여부를 선택할 수 있습니다.
Zop 애플리케이션 서버를 사용하여 Python으로 작성된 데이터는 MySQL에 저장됩니다. Zenos로 할 수 있는
네트워크 서비스, 시스템 리소스, 장치 성능을 모니터링하고 Zenoss 코어는 환경을 분석합니다. 이를 통해 다수의 특정 장치를 신속하게 처리할 수 있습니다.
16. 전망대

모니터링 및 감시 시스템 네트워크 장치지원되는 장치 목록이 엄청나고 네트워크 장치에 국한되지는 않지만 장치는 SNMP를 지원해야 합니다.
17. 센트레온
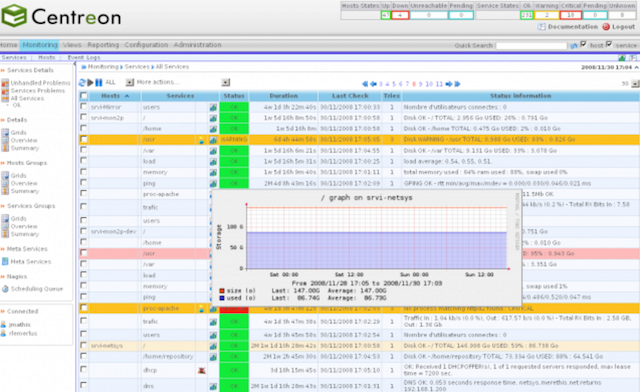
시스템 정보가 포함된 전체 인프라 및 애플리케이션을 제어할 수 있는 포괄적인 모니터링 시스템입니다. Nagios에 대한 무료 대안.
18. 신경절
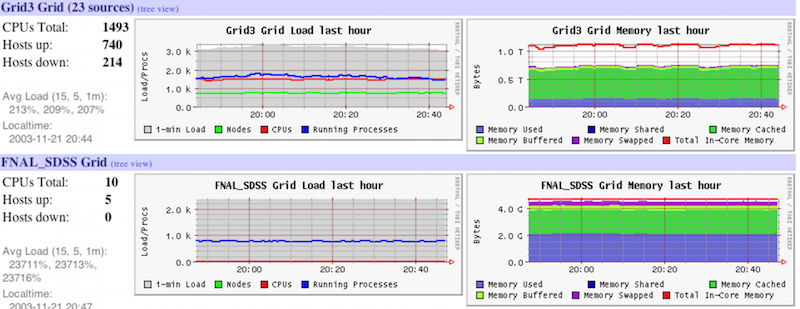
Ganglia는 고성능에 사용되는 확장 가능한 분산 모니터링 시스템입니다. 컴퓨팅 시스템클러스터 및 그리드와 같은. 모니터링되는 각 노드에 대한 통계 및 실시간 계산 기록을 추적합니다.
19.판도라 FMS
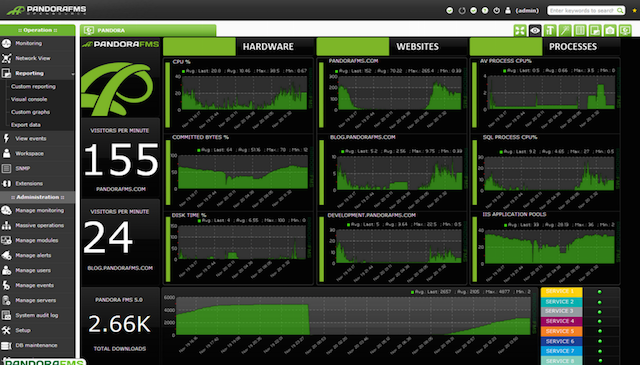
모니터링 시스템, 우수한 성능 및 확장성, 하나의 모니터링 서버는 수천 호스트의 작업을 제어할 수 있습니다.
20. 넷XMS

컴퓨터 시스템 및 네트워크 모니터링을 위한 오픈 소스 소프트웨어입니다.
21.OpenNMS

OpenNMS 모니터링 플랫폼. Nagios와 달리 SNMP, WMI 및 JMX를 지원합니다.
22.HypericHQ
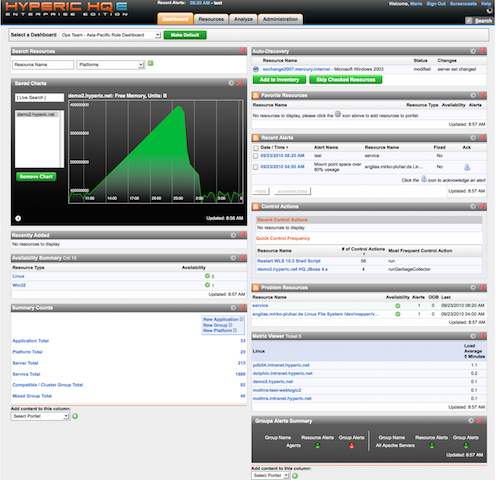
물리적, 가상 및 클라우드 환경에서 OS, 미들웨어 및 애플리케이션을 모니터링하는 데 사용되는 VMware vRealize Operations 제품군의 구성 요소입니다. 가상화 스택의 각 계층(vSphere 하이퍼바이저에서 게스트 OS까지)에서 가용성, 성능, 사용량, 이벤트, 로그 및 변경 사항을 표시합니다.
23. 보순

StackExchange의 오픈 소스 모니터링 및 경고 시스템. Bosun은 잘 짜여진 데이터 스키마와 강력한 처리 언어를 갖추고 있습니다.
24. 센수
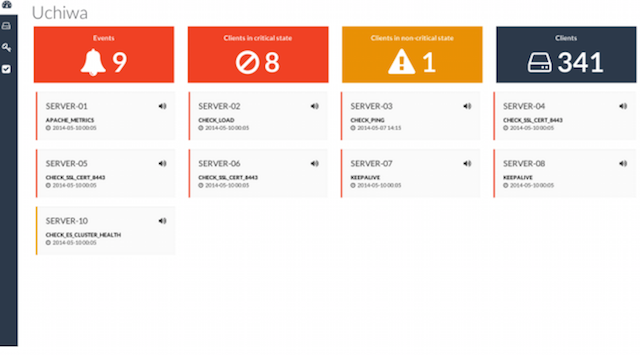
Sensu는 Nagios와 유사한 오픈 소스 경보 시스템입니다. 간단한 대시보드가 있으며 클라이언트, 확인 및 트리거된 경고 목록을 볼 수 있습니다. 프레임워크는 서버 통계를 수집하고 축적하는 데 필요한 메커니즘을 제공합니다. 각 서버에서 Sensu 에이전트(클라이언트)가 실행되며 스크립트 세트를 사용하여 서비스 상태, 서비스 상태를 확인하고 기타 정보를 수집합니다.
25. 콜렉트엠
CollectM은 10초마다 시스템 리소스 사용량에 대한 통계를 수집합니다. 여러 호스트에 대한 통계를 수집하여 서버로 보낼 수 있으며 정보는 그래프로 표시됩니다.
28. 로그의 성능 분석(PAL) 도구
34. 총 네트워크감시 장치
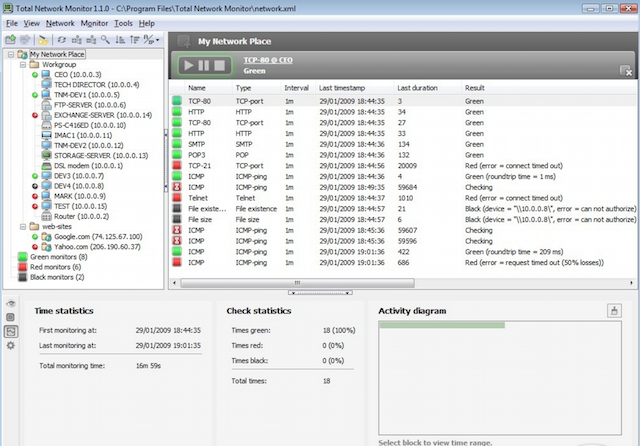
지속적인 모니터링 프로그램입니다. 지역 네트워크개별 컴퓨터, 네트워크 및 시스템 서비스. Total Network Monitor는 보고서를 생성하고 발생한 오류를 알려줍니다. 서비스, 서버 또는 파일 시스템: FTP, POP/SMTP, HTTP, IMAP, 레지스트리, 이벤트 로그, 서비스 상태 등.
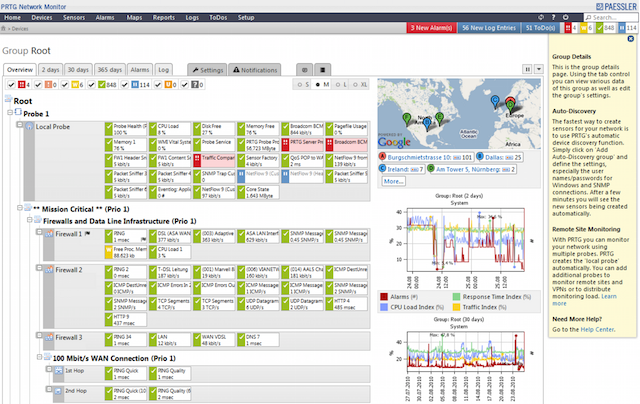
35.PRTG
40. ELM 엔터프라이즈 관리자
ELM Enterprise Manager - "발생한 일"에서 "진행 중인 일"까지 실시간으로 전체 모니터링. ELM의 모니터링 도구에는 이벤트 수집기, 성능 모니터, 서비스 모니터, 프로세스 모니터, 파일 모니터, PING 모니터가 포함됩니다.
41.이벤트 응모

42. 빔원
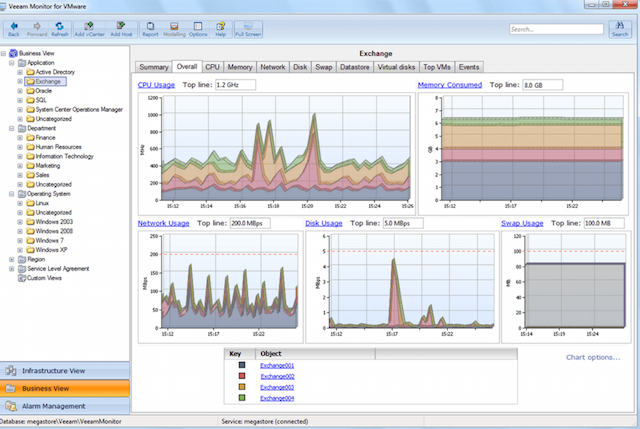
VMware, Hyper-V 및 Veeam 백업 및 복제 인프라를 위한 효율적인 모니터링, 보고 및 리소스 계획 솔루션은 IT 인프라의 상태를 모니터링하고 문제가 사용자 경험을 방해하기 전에 진단합니다.
43. CA 통합 인프라 관리(구 CA Nimsoft Monitor, Unicenter)

Windows 서버 리소스의 성능과 가용성을 모니터링합니다.
44.HP 운영 관리자

이 인프라 모니터링 소프트웨어는 사전 예방적 근본 원인 분석을 수행하여 복구 시간과 운영 관리 비용을 줄입니다. 이 솔루션은 자동화된 모니터링에 이상적입니다.
45. Dell 개방형 관리
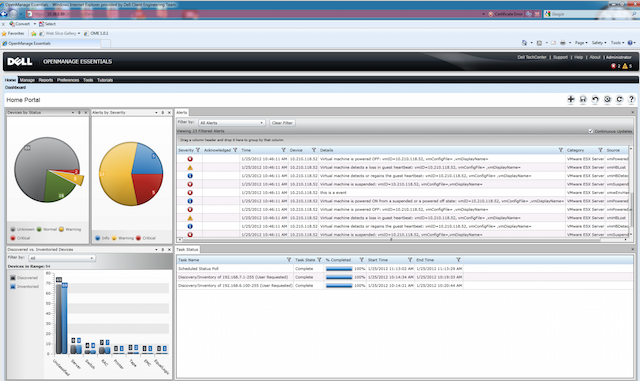
OpenManage(현재 Dell Enterprise Systems Management)는 올인원 모니터링 제품입니다.
46.할시온 윈도우 서버관리자
47. 토퍼 퍼프몬

서버를 모니터링하고 프로세스, 성능을 제어하는 데 사용됩니다.
48. BMC 순찰

IT 인프라 관리 및 모니터링 시스템.
50 과학 논리
Dude 모니터링 시스템은 무료이지만 전문가에 따르면 상용 제품보다 열등하지 않으며 개별 서버, 네트워크 및 네트워크 서비스를 모니터링합니다.
55. 대역폭D

오픈 소스 프로그램.
56. 나그비스

인프라 맵을 만들고 상태를 표시할 수 있는 Nagios용 확장입니다. NagVis는 다양한 위젯, 아이콘 세트를 지원합니다.
57Proc 넷 모니터
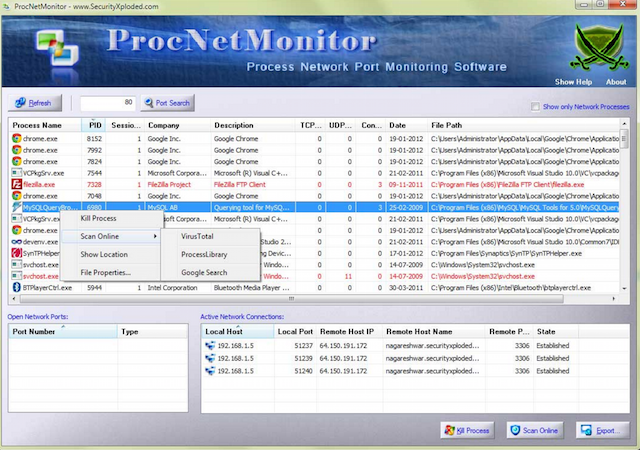
모든 활성 프로세스를 추적하고 필요한 경우 신속하게 중지하여 프로세서의 부하를 줄일 수 있는 무료 모니터링 응용 프로그램입니다.
58.핑플로터
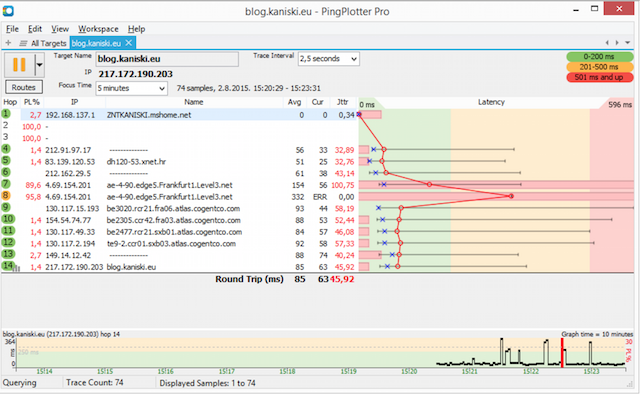
IP 네트워크를 진단하는 데 사용되며 손실 및 지연이 발생하는 위치를 결정할 수 있습니다. 네트워크 패킷.
작지만 유용한 도구
목록은 하드웨어 모니터링을 위한 몇 가지 옵션을 언급하지 않고는 완전하지 않습니다.60Glint 컴퓨터 활동 모니터
61.실제온도
![]()
온도 모니터링 유틸리티 인텔 프로세서, 설치가 필요하지 않으며 각 코어의 현재, 최소 및 최대 온도와 조절 시작을 추적합니다.
62. 스피드팬
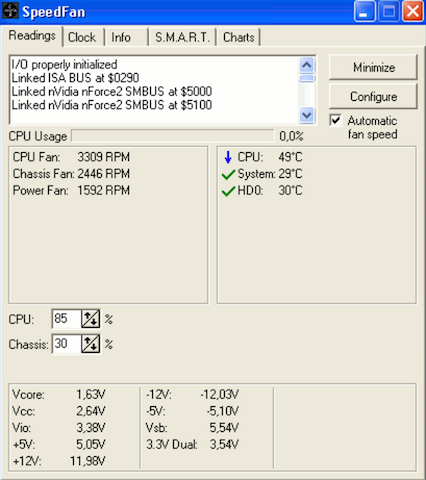
시스템에서 팬의 온도와 회전 속도를 제어하고 센서의 성능을 모니터링할 수 있는 유틸리티 마더보드, 비디오 카드 및 하드 드라이브.
63.오픈하드웨어모니터

Hyper-V 서버에서 CPU 사용량 모니터링
CPU 시간은 주요 하드웨어 자원 중 하나이므로 서버의 안정적인 운영을 위해서는 CPU 부하를 모니터링하는 것이 매우 중요합니다. 여기서 Hyper-V 서버의 CPU 모니터링은 일반 응용 프로그램 서버 모니터링과 다르다는 점을 알아야 합니다. 이것은 하이퍼바이저의 아키텍처 때문입니다.
사실 Hyper-V 역할을 설치한 후 시스템에 격리된 파티션(파티션)이 생성됩니다. 가상머신 운영을 위해 게스트(게스트) 파티션을 사용하고 호스트 OS 자체가 별도의 부모(루트) 파티션에서 작동하며 하드웨어 자원(프로세서, 메모리 등)의 분배는 하이퍼바이저에서 처리하며, 운영 체제가 아닙니다.
표준 성능 카운터는 호스트 OS의 상태만 모니터링하므로 판독값이 실제 부하를 반영하지 않을 수 있습니다. 이는 프로세서 부하를 모니터링할 때 특히 두드러지므로 Hyper-V를 모니터링하려면 일반 응용 프로그램 서버를 모니터링하기 위한 성능 카운터와 달리 특수 카운터를 사용해야 합니다.
Hyper-V에서 CPU 사용량을 모니터링하기 위한 세 가지 카운터 그룹이 있습니다.
Hyper-V 하이퍼바이저 논리 프로세서;
Hyper-V 하이퍼바이저 가상 프로세서;
Hyper-V 하이퍼바이저 루트 가상 프로세서.
Hyper-V 하이퍼바이저 논리 프로세서
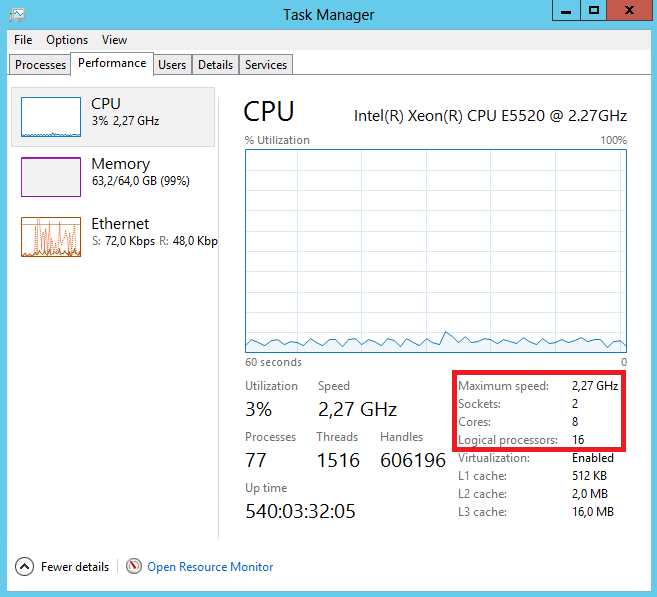
이것은 논리 프로세서당 CPU 로드를 표시하는 Hyper-V 카운터의 기본 그룹입니다. 논리적 프로세서에서 시스템은 물리적 프로세서 코어 또는 계산 스레드(하이퍼 스레딩을 사용할 때)를 이해한다는 것을 상기시켜 드리겠습니다.
메모.성능 섹션의 작업 관리자에서 논리 프로세서 수를 볼 수 있습니다. 따라서 우리 서버에는 각각 4개의 코어(총 8개의 물리적 코어)가 있는 2개의 프로세서가 있으며 하이퍼 스레딩이 활성화되어 총 16개의 논리적 프로세서를 제공합니다.
Hyper-V Hypervisor 논리 프로세서를 사용하면 총 부하(_Total)와 각 논리 프로세서(LP)를 별도로 표시할 수 있습니다. 총 부하를 모니터링하기 위한 주요 카운터는 다음과 같습니다.
% 게스트 실행 시간- 생성된 프로세서의 부하 가상 머신;
% 하이퍼바이저 실행 시간- 하이퍼바이저 자체에 의해 생성된 프로세서의 부하, 즉 가상 머신에 서비스를 제공하는 하이퍼바이저가 소비한 CPU 시간의 백분율
% 총 실행 시간- 프로세서의 총 부하는 이전 두 카운터의 합계입니다.

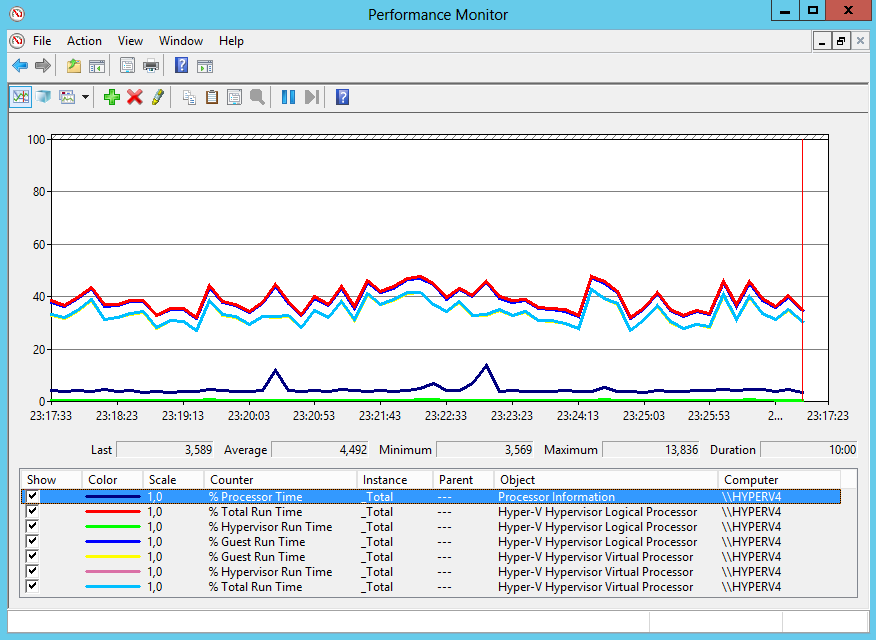
부하 그래프를 보고 결과를 기존 프로세서 부하 카운터(% Processor Time)가 표시하는 것과 비교하면 흥미로운 상황이 전개됩니다. 기존 카운터에 따르면 프로세서 부하가 약 4%인 경우 하이퍼바이저 카운터(총 실행 시간 %)는 평균 부하가 40%임을 나타냅니다. 그들이 말했듯이 차이를 느끼십시오 🙂

Hyper-V 하이퍼바이저 가상 프로세서
가상 프로세서는 논리 프로세서와 동일한 코어/컴퓨팅 스레드이지만 하이퍼바이저의 관점에서 볼 수 있습니다.
Hyper-V 하이퍼바이저 가상 프로세서는 가상 머신에서 생성된 CPU 부하를 보여줍니다. 가상 프로세서(VP)는 가상 머신 소속별로 그룹화되어 각 개별 머신에서 생성된 부하를 추정할 수 있으며 총 값(_Total)은 게스트 OS에서 생성된 총 부하를 나타냅니다.
가상 프로세서에는 다양한 카운터가 있지만 주요 카운터는 이전 경우와 동일합니다.
% 게스트 실행 시간- 하이퍼바이저와 관련이 없는 자체 작업에 대해 가상 머신이 소비한 프로세서 시간의 백분율
% 하이퍼바이저 실행 시간- 하이퍼바이저와 관련된 작업에서 가상 머신이 소비한 CPU 시간의 백분율
% 총 실행 시간- 가상 머신에 의해 생성된 프로세서의 총 부하. 이전 두 카운터의 합입니다.
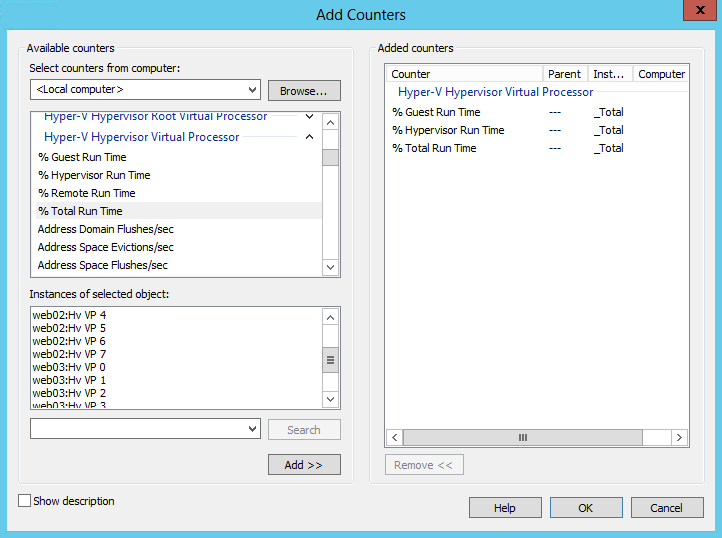
명확성을 위해 가상 머신에서 생성된 부하의 그래프입니다.
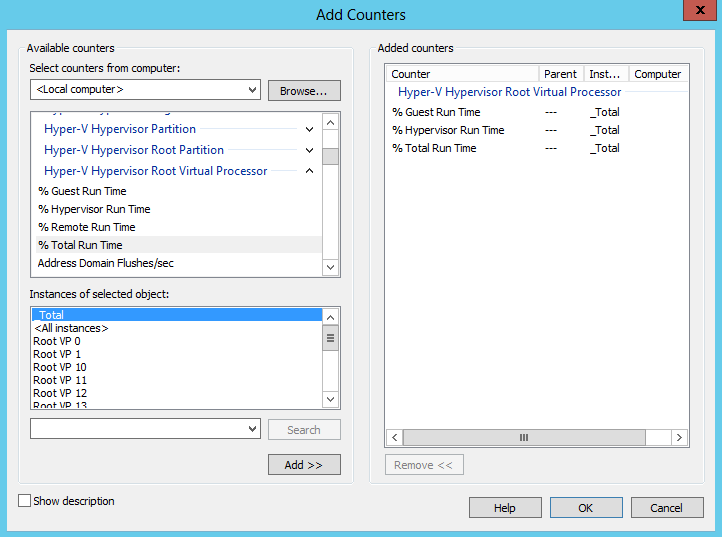
Hyper-V 하이퍼바이저 루트 가상 프로세서
Hyper-V 하이퍼바이저 루트 가상 프로세서에는 Hyper-V 하이퍼바이저 가상 프로세서와 동일한 카운터 집합이 포함되어 있습니다. 차이점은 Hyper-V 하이퍼바이저 루트 가상 프로세서에는 기본 파티션(루트 파티션)에서 작동하는 호스트 OS에 대한 카운터만 포함되어 있다는 것입니다.
% 게스트 실행 시간- 호스트가 하이퍼바이저와 관련이 없는 작업에 소비한 CPU 시간의 백분율
% 하이퍼바이저 실행 시간하이퍼바이저를 서비스하는 호스트 시스템이 소비한 CPU 시간의 백분율입니다.
% 총 실행 시간- 호스트 OS에 의해 생성된 프로세서의 총 부하. 이전 카운터의 합계를 나타냅니다.
요약 그래프는 루트 가상 프로세서 및 가상 프로세서에 대한 총 실행 시간 %를 합산하면 논리 프로세서에 대한 총 실행 시간 % 및 루트 가상 프로세서에 대한 총 실행 시간 % 값이 대략적으로 일치한다는 것을 보여줍니다. 표준 프로세서 카운터 % 프로세서 시간.
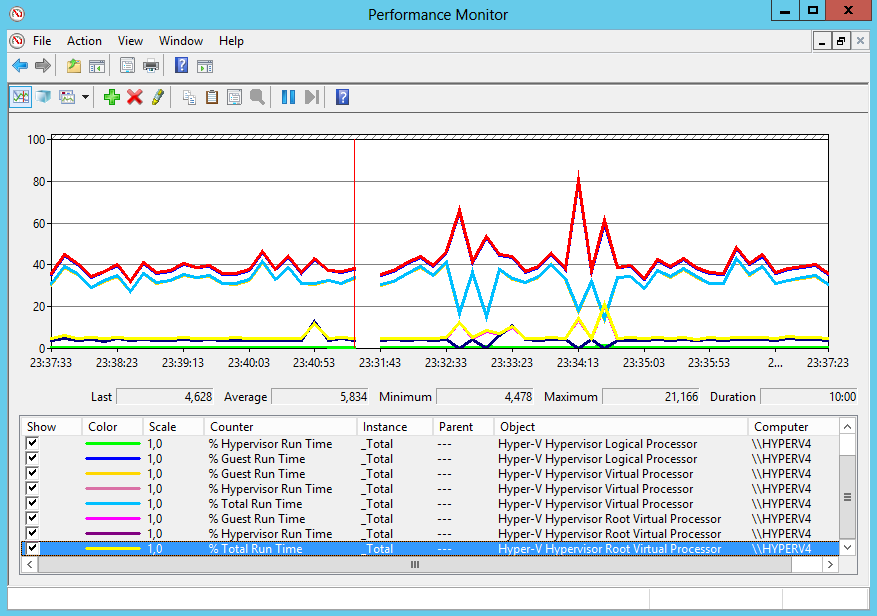
가상 머신을 제외하고 호스트 시스템의 부하만 표시하기 때문에 표준 프로세서 카운터 % Processor Time에 집중해서는 안 된다는 결론을 내렸습니다. 가장 정확한 CPU 로드 결과는 Hyper-V 서버의 로드를 모니터링하는 데 사용해야 하는 Hyper-V 하이퍼바이저 논리 프로세서 카운터 집합에 의해 표시됩니다.

 Editor's Choice 스마트폰 ZTE Blade X3 화이트
Editor's Choice 스마트폰 ZTE Blade X3 화이트 휴대용 스피커 Sony SRS-XB20
휴대용 스피커 Sony SRS-XB20 스마트 폰 "Alcatel One Touch": 리뷰, 사양, 설정 및 리뷰
스마트 폰 "Alcatel One Touch": 리뷰, 사양, 설정 및 리뷰 Android에서 파일은 어디에 다운로드됩니까?
Android에서 파일은 어디에 다운로드됩니까?